人工智能

文章目录
人工智能定义
1946年2月14日,第一台计算机ENIAC诞生,在此后的70多年里,伴随着微处理器技术,互联网技术,计算机产业发展迅速,极大地改变了整个世界。对科技工作者而言,存在一个终极的梦想,让机器可以像人类一样思考,代替人类工作,即所谓的人工智能,简称AI。
美国斯坦福大学人工智能研究中心尼尔逊教授对人工智能下了这样一个定义:“人工智能是关于知识的学科–怎样表示知识以及怎样获得知识并使用知识的科学。”而另一个美国麻省理工学院的温斯顿教授认为:“人工智能就是研究如何使计算机去做过去只有人才能做的智能工作。”这些说法反映了人工智能学科的基本思想和基本内容。即人工智能是研究人类智能活动的规律,构造具有一定智能的人工系统,研究如何让计算机去完成以往需要人的智力才能胜任的工作,也就是研究如何应用计算机的软硬件来模拟人类某些智能行为的基本理论、方法和技术。
人工智能是研究使计算机来模拟人的某些思维过程和智能行为(如学习、推理、思考、规划等)的学科,主要包括计算机实现智能的原理、制造类似于人脑智能的计算机,使计算机能实现更高层次的应用。人工智能将涉及到计算机科学、心理学、哲学和语言学等学科。可以说几乎是自然科学和社会科学的所有学科,其范围已远远超出了计算机科学的范畴,人工智能与思维科学的关系是实践和理论的关系,人工智能是处于思维科学的技术应用层次,是它的一个应用分支。从思维观点看,人工智能不仅限于逻辑思维,要考虑形象思维、灵感思维才能促进人工智能的突破性的发展,数学常被认为是多种学科的基础科学,数学也进入语言、思维领域,人工智能学科也必须借用数学工具,数学不仅在标准逻辑、模糊数学等范围发挥作用,数学进入人工智能学科,它们将互相促进而更快地发展。
研究内容
- 数据挖掘 人工智能的一个很重要的方向是数据挖掘技术,这种技术的原理是用计算机进行数据分析,然后进行人性化的推荐和预测。比如,我们电脑上的广告是根据我们日常浏览网页的兴趣进行推荐的,微博上、网站上最显眼的也是我们最感兴趣的内容,这些都是计算机分析而得出的。本质上,这种技术发挥的功效与人类的“思考”是相类似的,虽不能完全对等,但现在也能够达到很好的辅助效果。
- 计算机视觉类 人工智能的一大方向是计算机视觉类,其中包括我们所熟悉的图像识别、视频识别、人脸识别等等。计算机视觉的精髓是教会计算机如何去"看”,也就是说,计算机视觉人工智能所要达到的终极目标是用摄影机和电脑替代我们人类的肉眼,这样识别出的图像或者测量出的数据会更准确。比较著名的是“人脸识别”,这属于现在比较流行的身份验证技术之一,通过摄像采集人脸的画面,转化为图像数据,再跟数据库当中的人脸特征信息作“点对点”对比,从而进行身份识别。
- 自然语言处理 人工智能的另外一大重要方向是自然语言处理技术,包括机器翻译、语音识别等等。其中语音识别是最核心、普及程度最高的一种自然语言处理技术。语音识别技术是将人语音当中的词汇内容识别出来,通过技术手段,转换为计算机可读取的内容。通俗点来说,就是要让机器学会“听人话”,让计算机作我们的“耳朵”。
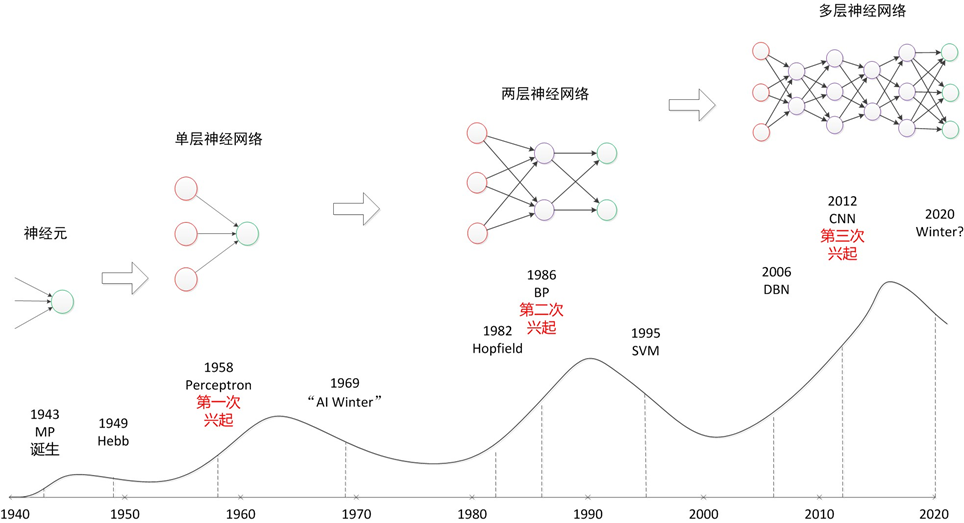
发展史
https://zh.wikipedia.org/wiki/人工智能史
-
人工智能的诞生:1943 - 1956:在20世纪40年代和50年代,来自不同领域(数学,心理学,工程学,经济学和政治学)的一批科学家开始探讨制造人工大脑的可能性。1956年,人工智能被确立为一门学科。
-
黄金年代:1956 - 1974: 达特茅斯会议之后的数年是大发现的时代。对许多人而言,这一阶段开发出的程序堪称神奇:[45]计算机可以解决代数应用题,证明几何定理,学习和使用英语。当时大多数人几乎无法相信机器能够如此“智能”。[46] 研究者们在私下的交流和公开发表的论文中表达出相当乐观的情绪,认为具有完全智能的机器将在二十年内出现。[47] DARPA(國防高等研究計劃署)等政府机构向这一新兴领域投入了大笔资金。
-
第一次AI低谷:1974 - 1980:到了70年代,AI开始遭遇批评,随之而来的还有资金上的困难。AI研究者们对其课题的难度未能作出正确判断:此前的过于乐观使人们期望过高,当承诺无法兑现时,对AI的资助就缩减或取消了。[70]同时,由于马文·闵斯基对感知器的激烈批评,联结主义(即神经网络)销声匿迹了十年。[71]70年代后期,尽管遭遇了公众的误解,AI在逻辑编程,常识推理等一些领域还是有所进展。[72]
-
繁荣:1980 - 1987:在80年代,一类名为“专家系统”的AI程序开始为全世界的公司所采纳,而“知识处理”成为了主流AI研究的焦点。日本政府在同一年代积极投资AI以促进其第五代计算机工程。80年代早期另一个令人振奋的事件是John Hopfield和David Rumelhart使联结主义重获新生。AI再一次获得了成功。
-
第二次AI低谷:1987 - 1993:80年代中商业机构对AI的追捧与冷落符合经济泡沫的经典模式,泡沫的破裂也在政府机构和投资者对AI的观察之中。尽管遇到各种批评,这一领域仍在不断前进。来自机器人学这一相关研究领域的Rodney Brooks和Hans Moravec提出了一种全新的人工智能方案。
-
AI:1993 - 2011:现已年过半百的AI终于实现了它最初的一些目标。它已被成功地用在技术产业中,不过有时是在幕后。这些成就有的归功于计算机性能的提升,有的则是在高尚的科学责任感驱使下对特定的课题不断追求而获得的。不过,至少在商业领域里AI的声誉已经不如往昔了。“实现人类水平的智能”这一最初的梦想曾在60年代令全世界的想象力为之着迷,其失败的原因至今仍众说纷纭。各种因素的合力将AI拆分为各自为战的几个子领域,有时候它们甚至会用新名词来掩饰“人工智能”这块被玷污的金字招牌。[129]AI比以往的任何时候都更加谨慎,却也更加成功。
-
深度学习,大数据和人工智能:2011至今:进入21世纪,得益于大数据和计算机技术的快速发展,许多先进的机器学习技术成功应用于经济社会中的许多问题。麦肯锡全球研究院在一份题为《大数据:创新、竞争和生产力的下一个前沿领域》的报告中估计,到2009年,美国经济所有行业中具有1000名以上员工的公司都至少平均拥有一个200兆兆字节的存储数据。
到2016年,AI相关产品、硬件、软件等的市场规模已经超过80亿美元,纽约时报评价道AI已经到达了一个热潮。大数据应用也开始逐渐渗透到其他领域,例如生态学模型训练、经济领域中的各种应用、医学研究中的疾病预测及新药研发等。深度学习(特别是深度卷积神经网络和循环网络)更是极大地推动了图像和视频处理、文本分析、语音识别等问题的研究进程。
硬件方案
AI领域的核心计算是矩阵计算和卷积,其特点是计算量大,运算可拆分。从时间上看,经历了从纯cpu计算,GPU加速计算,专用硬件加速几个阶段。

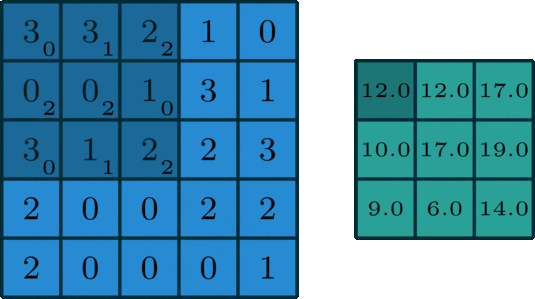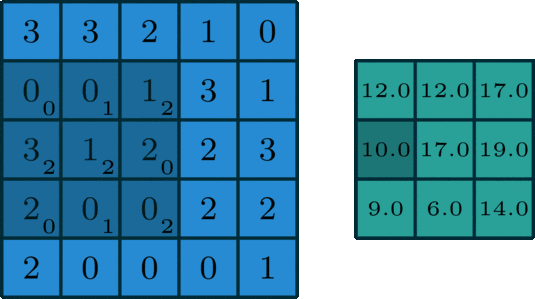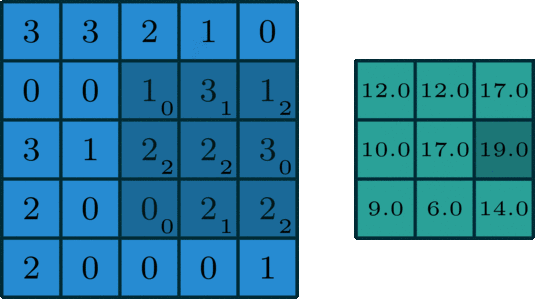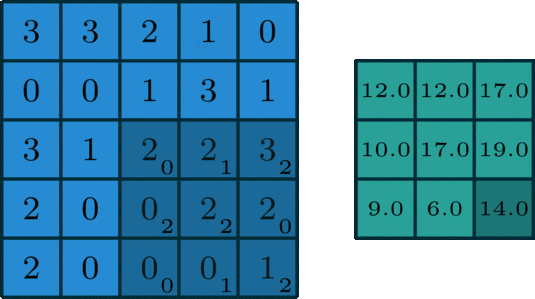
CPU是一个有多种功能的优秀领导者。它的优点在于调度、管理、协调能力强,计算能力则位于其次。而GPU相当于一个接受CPU调度的“拥有大量计算能力”的员工。
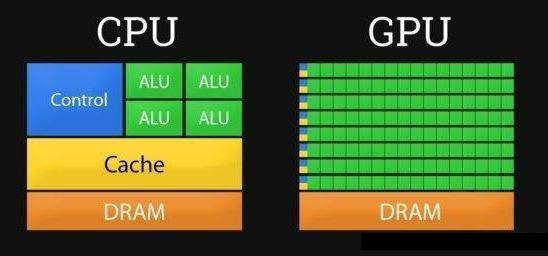
CPU
CPU 有强大的调度、管理、协调能力。应用范围广。开发方便且灵活。但其在大量数据处理上没有 GPU 专业,相对运算量低,但功耗不低。
GPU
相比CPU,GPU由于更适合执行复杂的数学和几何计算(尤其是并行运算),刚好与包含大量的并行运算的人工智能深度学习算法相匹配。
GPU 作为图像处理器,设计初衷是为了应对图像处理中需要大规模并行计算。因此,其在应用于深度学习算法时,有三个方面的局限性:
第一, 应用过程中无法充分发挥并行计算优势。深度学习包含训练和应用两个计算环节,GPU 在深度学习算法训练上非常高效,但在应用时一次性只能对于一张输入图像进行处理, 并行度的优势不能完全发挥。
第二, 硬件结构固定不具备可编程性。深度学习算法还未完全稳定,若深度学习算法发生大的变化,GPU 无法像 FPGA 一样可以灵活的配置硬件结构。
第三, 运行深度学习算法能效远低于 FPGA。学术界和产业界研究已经证明,运行深度学习算法中实现同样的性能,GPU 所需功耗远大于 FPGA,例如国内初创企业深鉴科技基于 FPGA 平台的人工智能芯片在同样开发周期内相对 GPU 能效有一个数量级的提升。
其功耗高,目前常用于云端计算处理上。
ASIC
定制芯片成本最低,功耗低,而且适合量产。
但由于其研发成本(开模成本)高昂,开发周期和验证周期长。对于很多厂商来说压力巨大。目前在人工智能领域风险高。
目前人工智能算法日新月异,变化快速,对于需要高成本,高研发周期的 ASIC 相对来说是不适用的。应用相对较少。
FPGA
可以通过硬件编程实现功能。
FPGA 同时拥有流水线并行和数据并行。可以实现比 GPU 更高的并发处理。
在密集处理和高并发上能力上占优,而且功耗比 CPU,GPU 低。
但其缺点有:
第一,基本单元的计算能力有限。为了实现可重构特性,FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠 LUT 查找表)都远远低于 CPU 和 GPU 中的 ALU模块。
第二,速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距。
第三,FPGA 价格比起 ASIC 较为昂贵,在规模放量的情况下单块 FPGA 的成本要远高于专用定制芯片。
主流深度学习硬件速度对比
(Colab TPU) 速度 382s/epoch
(i5 8250u) 速度 320s/epoch
(i7 9700k) 速度 36s/epoch
(GPU MX150) 速度 36s/epoch
(Colab GPU) 速度 16s/epoch
(GPU GTX 1060) 速度 9s/epoch
(GPU GTX1080ti) 速度 4s/epoch
通过对比看出相较于普通比较笔记本的(i5 8250u)CPU,一个入门级显卡(GPU MX150)可以提升8倍左右的速度,而高性能的显卡(GPU GTX1080ti)可以提升80倍的速度,如果采用多个GPU将会获得更快速度,所以经常用于训练的话还是建议使用GPU。
Google TPU
张量处理器(英语:Tensor Processing Unit,缩写:TPU)是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。
与GPU相比,TPU采用低精度(8位)计算,以降低每步操作使用的晶体管数量,这对于深度学习的准确度来说影响很小,却可以大幅降低功耗、加快运算速度。同时,TPU使用了脉动阵列的设计,用来优化矩阵乘法与卷积运算,减少I/O操作。利用自身更大的片上内存,来减少对DRAM的访问,从而更大程度地提升性能。
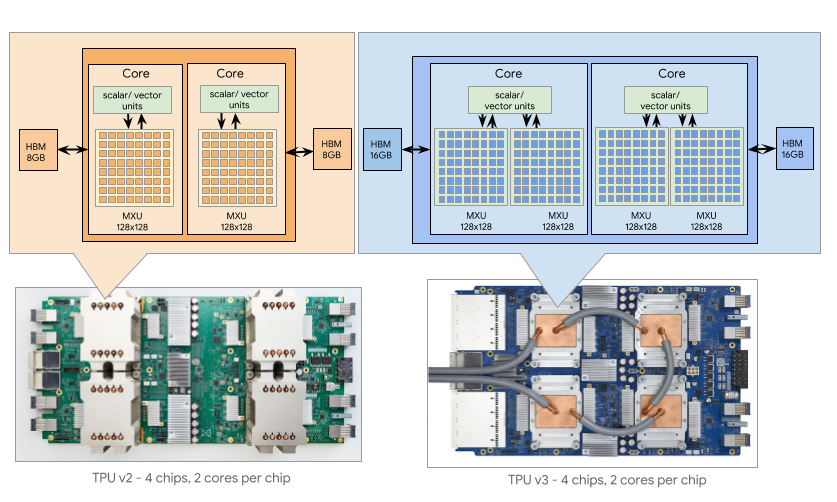
TPU v1 计算力 92 Teraflops,8Gb 内存,34GB/s 内存带宽,只能做推理(其实这是个 PCI-E 的加速卡,上面插了两条2133Mhz DDR3的内存)——它的光荣成绩是打败了李世石(4 个TPU推演,GPU 训练的 AlphaGo Lee 版本)
TPU v2 计算力 45Teraflops,16Gb 内存,600GB/s内存带宽(和显卡学习集成的 HBM),看起来单 TPU计算力慢了不少?既可以做训练,也能够推理——它的光荣成绩是打败了柯洁和一大堆其他人类高手(4个 TPU 推演,TPUv2 Pod训练的 AlphaGo Master版本,之后的 AlphaGo Zero 也诞生在这上面)
华为昇腾910
跟之前公布的参数一样,昇腾910是目前单芯片计算密度最大的芯片,采用7nm增强版EUV工艺,单Die内建32颗达芬奇核心,半精度(FP16)算力达到256 Tera-FLOPS,整数精度 (INT8) 算力达到512 Tera-OPS,最大功耗为350W。支持128通道 全高清 视频解码器- H.264/265。

NVIDIA v100
Tesla V100是基于Volta架构的产品,内置了5120个CUDA单元,核心频率为1455MHz,搭载16GB HBM2显存,单精度浮点性能15 TFLOPS,双精度浮点7.5 TFLOPS,显存带宽900GB/s。此外,Tesla V100还增加与深度学习高度相关的Tensor单元,Tensor性能号称可以达到120 TFLOPS。
intel
美国时间11月12日周二,英特尔终于正式宣布了首个针对复杂深度学习神经网络处理器:Nervana NNP。全称 Nervana Neural Network Processor,这是英特尔推出的第一款面向数据中心客户,针对复杂深度学习的专用 ASIC 芯片。芯片的命名来自于英特尔在 2016 年所收购的神经计算公司 Nervana。

Nervana NNP 芯片家族有三个最主要的亮点:计算密度更高,能效更好,采用英特尔架构+开源的全堆栈软件支持。在推理方面,NNP-I 最大的优势在于具有能效高、成本低,且其外形规格灵活,非常适合使用灵活的规格在现实世界中运行密集的多模式推理。
NNP-I 的工作功耗大约在15W左右,它能够和数据中心企业用户自己的技术实现完美的结合,部署更快、更高效的推理计算。英特尔面向了百度、 Facebook 等前沿人工智能客户,并针对他们的人工智能处理需求进行了定制开发。比如当 NNP-I 和 Facebook Glow 编译器结合时,可以对计算机视觉等工作负载实现显著优化,在实现高性能的同时节约更多的能源。
高通
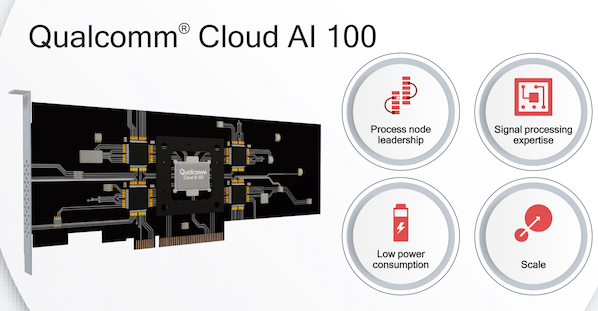
高通产品管理副总裁Ziad Asghar在介绍Cloud AI 100时,列出了高通在四个方面的优势,包括采用先进的7nm工艺、规模化、信号处理技术,以及低功耗设计专长
amazon
该芯片能够与TensorFlow和PyTorch等主要框架协同工作,并兼容亚马逊机器学习服务SageMaker和AWS 的EC2实例类型。Inferentia还将与Elastic Inference合作,以便加速GPU芯片部署AI的使用。
Inferentia检测主要框架何时与EC2实例一起使用,而且能够在每个芯片上获得数百个TOPS,用户也可以将这些顶级数据捆绑在一起以获得数千个TOPS。从这些数据种可以找出哪些部分从加速中受益最多, 然后将这部分数据移动到弹性推理以提高效率。
目前推出AI模型所需的两个主要流程是培训和推理,推理占了近90%的成本。
亚马逊的工程师则认为运营成本可以通过Elastic Inference节省75%的成本,如果Inferentia投入使用,成本还将降低十个百分点,这将是一个重大变革。
“你将能够在每个芯片上获得数百个TOPS; 如果你愿意的话,你可以将它们捆绑在一起以获得数千个TOPS,“AWS首席执行官Andy Jassy今天在年度re:Invent会议上表示。
Inferentia预览中还提供了许多不需要预先知道如何构建或训练AI模型的服务,包括Textract——一种用于从文档中提取文本的服务,和Personalize——一种用于向客户提供个性化建议的AI模型,以及Amazon Forecast——一种生成私有预测模型的服务。
Zion 是 Facebook 的下一代大容量统一训练平台,目标是高效地承担未来的更大计算负载。Zion 在设计时就考虑了如何高效地处理 CNN、LSTM、稀疏神经网络等多种不同的神经网络模型。Zion 平台可以提供高内存容量、高带宽、灵活的高速内部连接,为 Facebook 内部的关键工作负载提供强大的计算能力。
Zion 的设计采用了 Facebook 新的供应商透明的 OCP 加速模型(OAM)。OAM 的作用在于,Facebook 从 AMD、Habana、Graphcore、英特尔、英伟达等许多不同的硬件供应商处购买硬件,只要他们在开放计算计划(OCP)的公开标准基础上开发硬件,不仅可以帮助他们更快地创新,也可以让 Facebook 自由地在同一个机架上的不同的硬件平台、不同的服务器之间拓展,只需要通过一个机柜网络交换机。即便 Facebook 的 AI 训练负载不断增加、不断变得更加复杂,Zion 平台也可以拓展并处理。
具体来说,Facebook 的 Zion 系统可以分为三个部分:八路 CPU 服务器、OCP 加速模块、以及可以安装八个 OCP 加速模块的平台主板。

baidu XPU
在加州Hot Chips大会上,百度发布XPU,这是一款256核、基于FPGA的云计算加速芯片。合作伙伴是赛思灵(Xilinx)。XPU的目标是在性能和效率之间实现平衡,并处理多样化的计算任务。FPGA加速器本身很擅长处理某些计算任务,但随着许多小内核交织在一起,多样性程度将会上升。

理论基础
神经元模型
https://www.cnblogs.com/maybe2030/p/5597716.html
神经网络目前最广泛的一种定义:“神经网络是由具有适应性的简单单元组成的广泛并行互联的网络,它的组织能够模拟生物神经系统对真实事件物体所作出的交互反应”
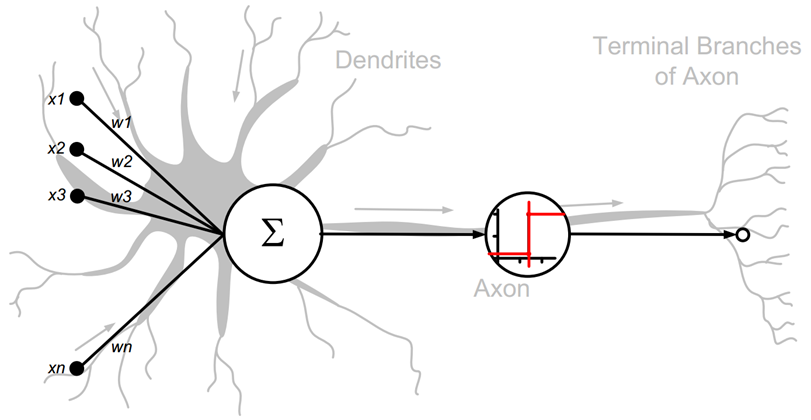
抽象的神经元模型

分类
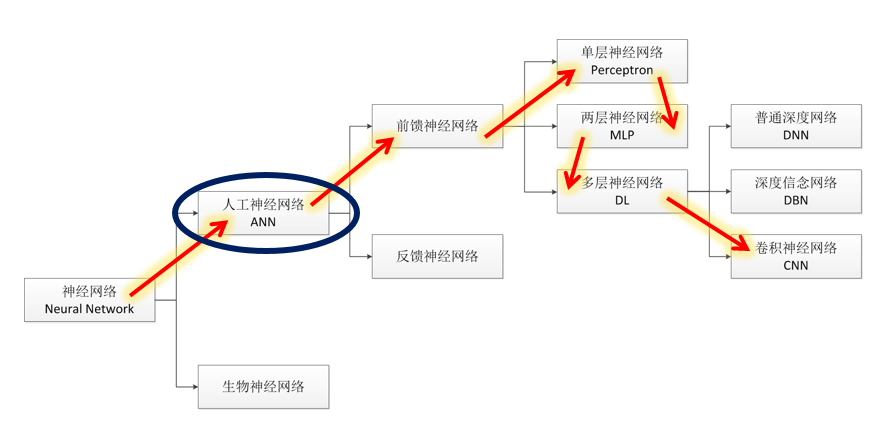
演进史
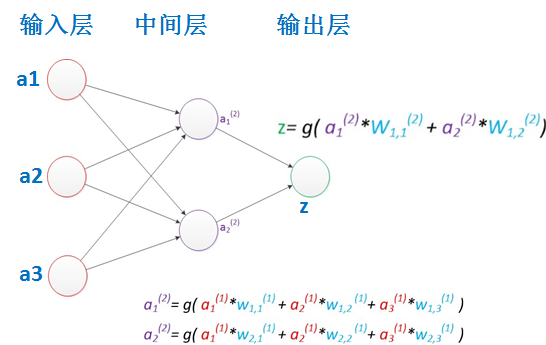
两层神经网络
两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层和输出层都是计算层。当增加一个计算层以后,两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。
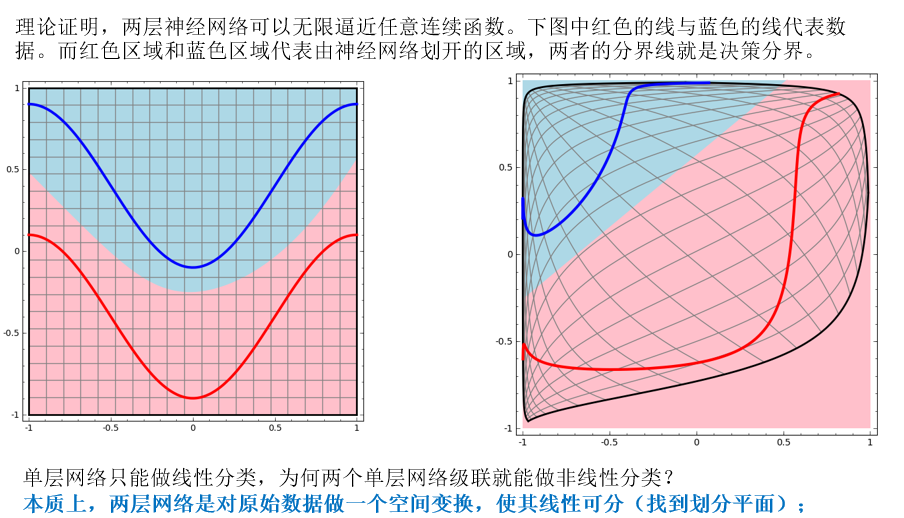
bp算法
所谓神经网络的训练或者是学习,其主要目的在于通过学习算法得到神经网络解决指定问题所需的参数,这里的参数包括各层神经元之间的连接权重以及偏置等。
计算过程详见 https://cloud.tencent.com/developer/news/151178
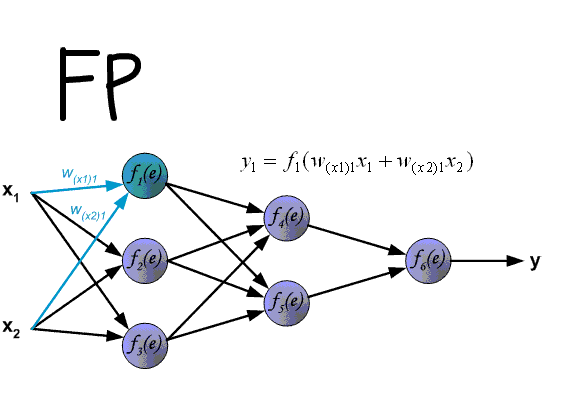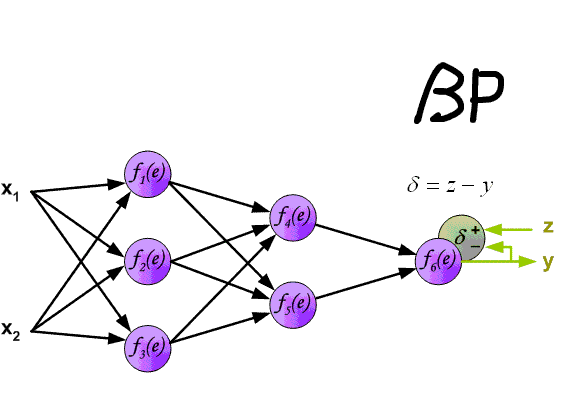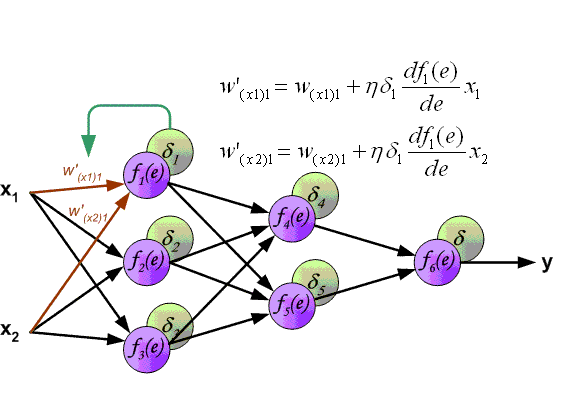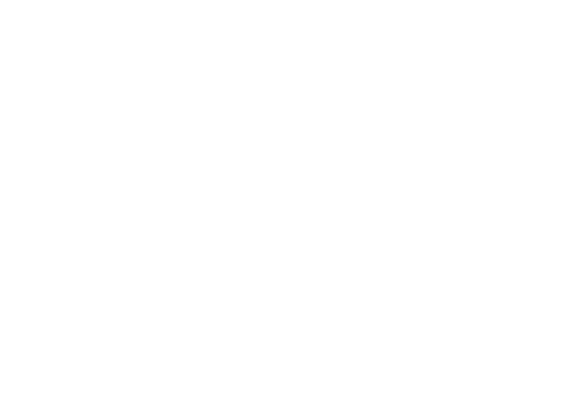
BP算法的主要流程可以总结如下:
输入:训练集D=(xk,yk)mk=1D=(xk,yk)k=1m; 学习率;
过程:
1. 在(0, 1)范围内随机初始化网络中所有连接权和阈值
2. repeat:
3. for all (xk,yk)∈D(xk,yk)∈D do
4. 根据当前参数计算当前样本的输出;
5. 计算输出层神经元的梯度项;
6. 计算隐层神经元的梯度项;
7. 更新连接权与阈值
8. end for
9. until 达到停止条件
输出:连接权与阈值确定的多层前馈神经网络
BP算法存在的问题:
- 局部最小值问题: 局部最小并非全局最小;
- 算法速度: 全连接的特性导致网络规模较大时算法的运算开销太大。
lenet-5
https://www.cnblogs.com/wuliytTaotao/p/9544625.html
是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
LeNet-5 大约有 60,000 个参数。
卷积特征提取

pooling下采样

LenNet-5共有7层(不包括输入层),每层都包含不同数量的训练参数,如下图所示。
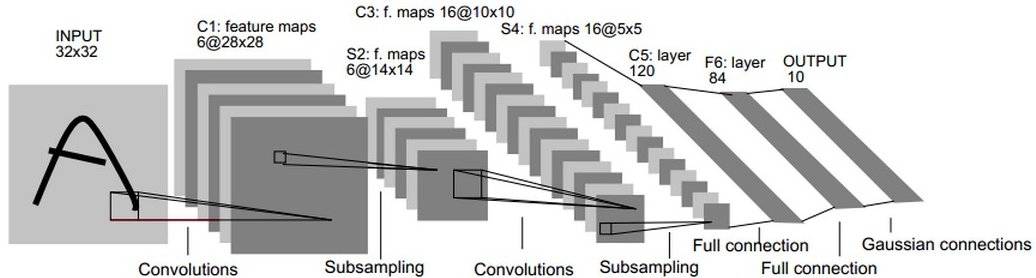
LeNet-5中主要有2个卷积层、2个池化层、3个全连接层3种连接方式
卷积层 卷积层采用的都是5x5大小的卷积核/过滤器,且卷积核每次滑动一个像素,一个特征图谱使用同一个卷积核. 每个上层节点的值乘以连接上的参数,把这些乘积及一个偏置参数相加得到一个和,把该和输入激活函数,激活函数的输出即是下一层节点的值
LeNet-5的池化层 下抽样层采用的是2x2的输入域,即上一层的4个节点作为下一层1个节点的输入,且输入域不重叠,即每次滑动2个像素,下抽样节点的结构如下:
每个下抽样节点的4个输入节点求和后取平均,均值乘以一个参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。
卷积后输出层矩阵宽度的计算: Outlength= (inlength-fileterlength+2*padding)/stridelength+1
Outlength:输出层矩阵的宽度 Inlength:输入层矩阵的宽度 Padding:补0的圈数
Stridelength:步长
LeNet-5第一层:卷积层C1 C1层是卷积层,形成6个特征图谱。卷积的输入区域大小是5x5,每个特征图谱内参数共享,即每个特征图谱内只使用一个共同卷积核,卷积核有5x5个连接参数加上1个偏置共26个参数。卷积区域每次滑动一个像素,这样卷积层形成的每个特征图谱大小是(32-5)/1+1=28x28。C1层共有26x6=156个训练参数,有(5x5+1)x28x28x6=122304个连接。
LeNet-5第二层:池化层S2 S2层是一个下采样层。C1层的6个28x28的特征图谱分别进行以2x2为单位的下抽样得到6个14x14((28-2)/2+1)的图。每个特征图谱使用一个下抽样核。5(S2中的每个像素都与C1中的2∗2个像素和1个偏置相连接)x14x14x6=5880个连接。
LeNet-5第三层:卷积层C3 C3层是一个卷积层,卷积和和C1相同,不同的是C3的每个节点与S2中的多个图相连。C3层有16个10x10(14-5+1)的图,每个图与S2层的连接的方式如下表 所示。C3与S2中前3个图相连的卷积结构见下图.这种不对称的组合连接的方式有利于提取多种组合特征。该层有(5x5x3+1)x6 + (5x5x4 + 1) x 3 + (5x5x4 +1)x6 + (5x5x6+1)x1 = 1516个训练参数,共有1516x10x10=151600个连接。
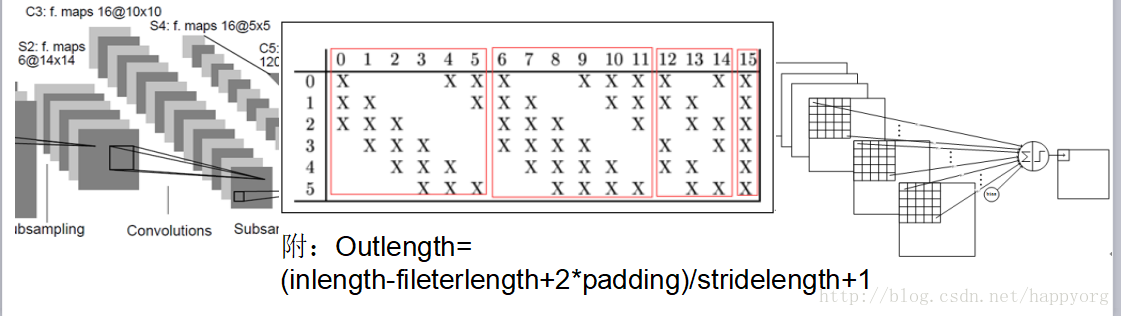
LeNet-5第四层:池化层S4 S4是一个下采样层。C3层的16个10x10的图分别进行以2x2为单位的下抽样得到16个5x5的图。5x5x5x16=2000个连接。连接的方式与S2层类似。
LeNet-5第五层:全连接层C5 C5层是一个全连接层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。
LeNet-5第六层:全连接层F6 F6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,该层的训练参数和连接数都是(120 + 1)x84=10164.
LeNet-5第七层:全连接层Output Output层也是全连接层,共有10个节点,分别代表数字0到9,如果节点i的输出值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。该层有84x10=840个设定的参数和连接。
以上是LeNet-5的卷积神经网络的完整结构,共约有60,840个训练参数,340,908个连接。
LeNet-5的训练算法 训练算法与传统的BP算法差不多。主要包括4步,这4步被分为两个阶段: 第一阶段,向前传播阶段: a)从样本集中取一个样本(X,Yp),将X输入网络; b)计算相应的实际输出Op。 在此阶段,信息从输入层经过逐级的变换,传送到输出 层。这个过程也是网络在完成训练后正常运行时执行的过程。在此过程中,网络执行的是计算(实际上就是输入与每层的权值矩阵相点乘,得到最后的输出结果): Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n)) 第二阶段,向后传播阶段 a)算实际输出Op与相应的理想输出Yp的差; b)按极小化误差的方法反向传播调整权矩阵。
卷积神经网络的优点 卷积网络较一般神经网络在图像处理方面有 如下优点 a)输入图像和网络的拓扑结构能很好的吻合; b)特征提取和模式分类同时进行,并同时在训练中产生; c)权重共享可以减少网络的训练参数,使神经网络结构变得更简单,适应性更强。 总结 卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式。
LaNet-5的局限性 CNN能够得出原始图像的有效表征,这使得CNN能够直接从原始像素中,经过极少的预处理,识别视觉上面的规律。然而,由于当时缺乏大规模训练数据,计算机的计算能力也跟不上,LeNet-5 对于复杂问题的处理结果并不理想。
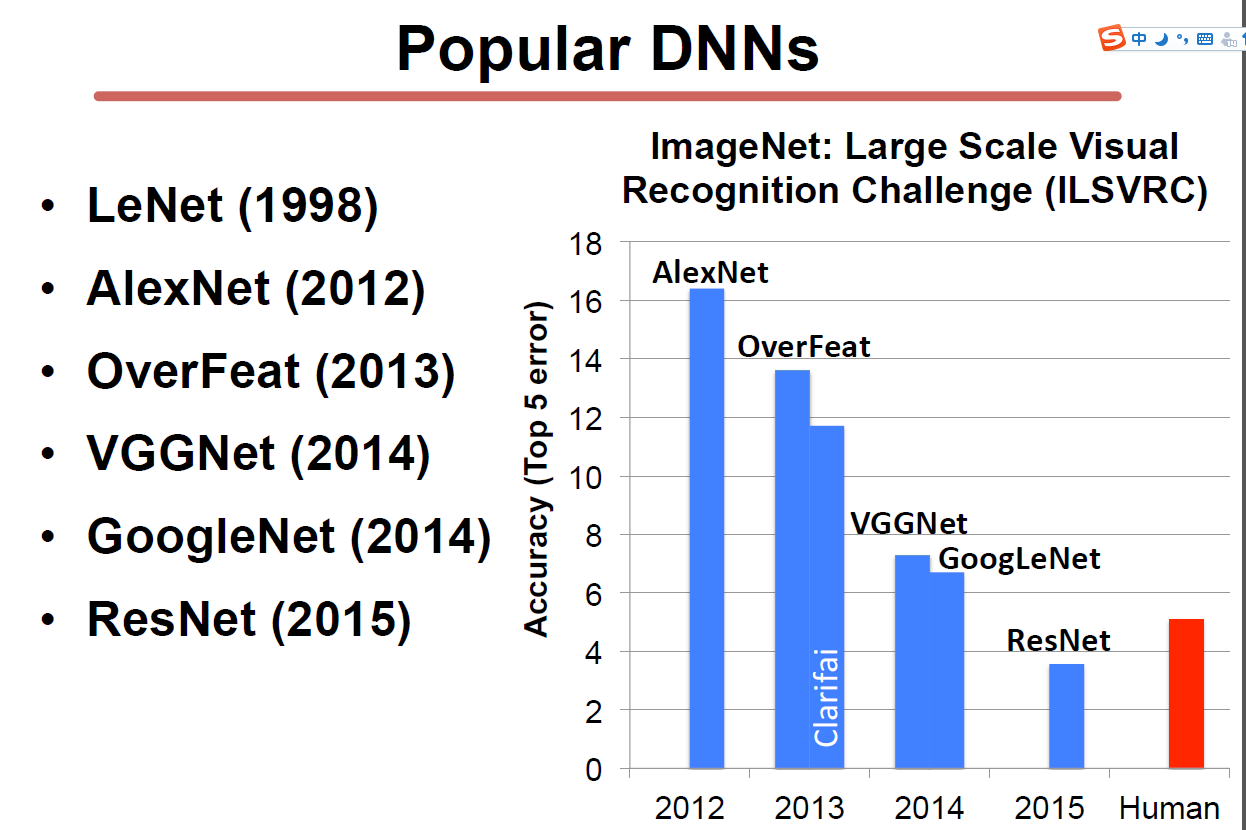
alexnet
2012年,Imagenet比赛冠军的model——Alexnet [2](以第一作者alex命名)。说实话,这个model的意义比后面那些model都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,确实让CNN和GPU都大火了一把,顺便推动了有监督DL的发展。
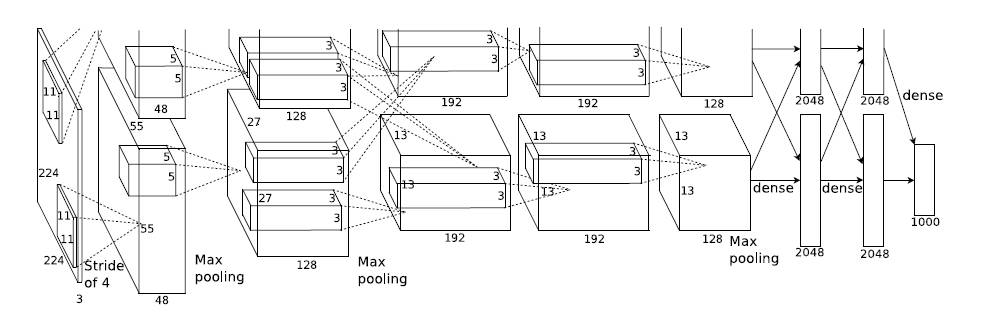
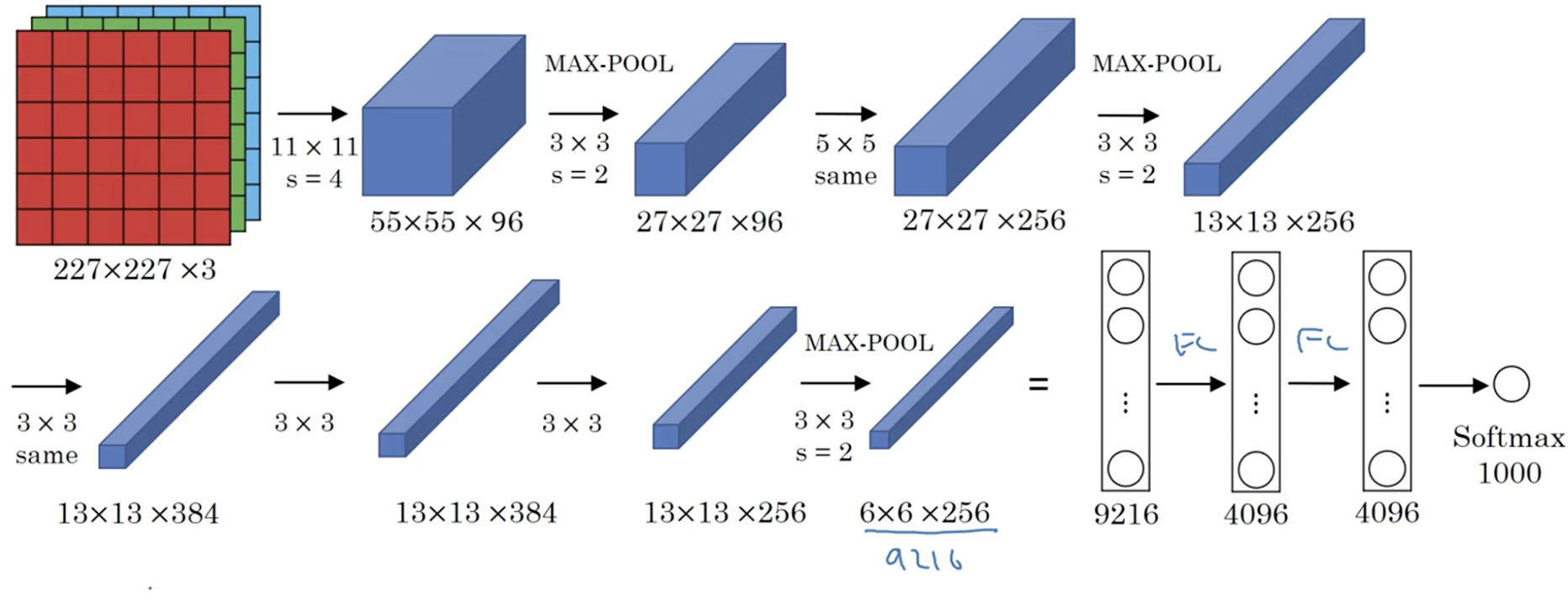
- 输入层:图像大小为 227×227×3,其中 3 表示输入图像的 channel 数(R,G,B)为 3。
- 卷积层:filter 大小 11×11,filter 个数 96,卷积步长 s=4s=4。(filter 大小只列出了宽和高,filter矩阵的 channel 数和输入图片的 channel 数一样,在这里没有列出)
- 池化层:max pooling,filter 大小 3×3,步长 s=2s=2。
- 卷积层:filter 大小 5×5,filter 个数 256,步长 s=1s=1,padding 使用 same convolution,即使得卷积层输出图像和输入图像在宽和高上保持不变。
- 池化层:max pooling,filter 大小 3×3,步长 s=2s=2。
- 卷积层:filter 大小 3×3,filter 个数 384,步长 s=1s=1,padding 使用 same convolution。
- 卷积层:filter 大小 3×3,filter 个数 384,步长 s=1s=1,padding 使用 same convolution。
- 卷积层:filter 大小 3×3,filter 个数 256,步长 s=1s=1,padding 使用 same convolution。
- 池化层:max pooling,filter 大小 3×3,步长 s=2s=2;池化操作结束后,将大小为 6×6×256 的输出矩阵 flatten 成一个 9216 维的向量。
- 全连接层:neuron 数量为 4096。
- 全连接层:neuron 数量为 4096。
- 全连接层,输出层:softmax 激活函数,neuron 数量为 1000,代表 1000 个类别。
alexnet的特性
- 大约 60million 个参数;
- 使用 ReLU 作为激活函数。
Deep Residual Learning
2015年imgnet比赛冠军,分类效果甚至比人类更好
https://blog.csdn.net/u011808673/article/details/78836617
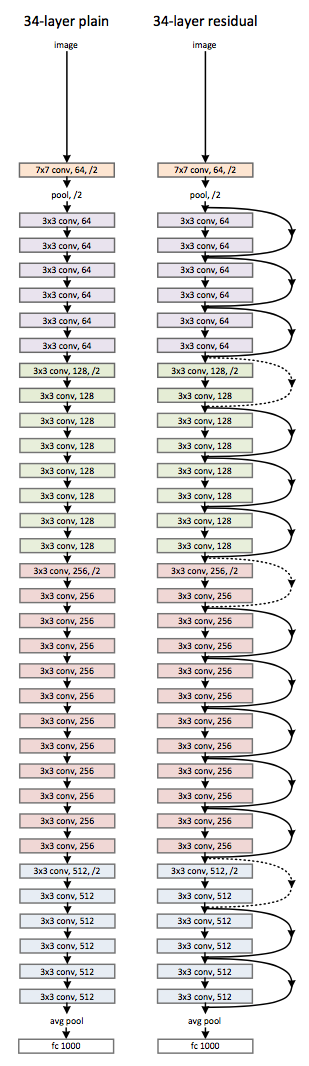
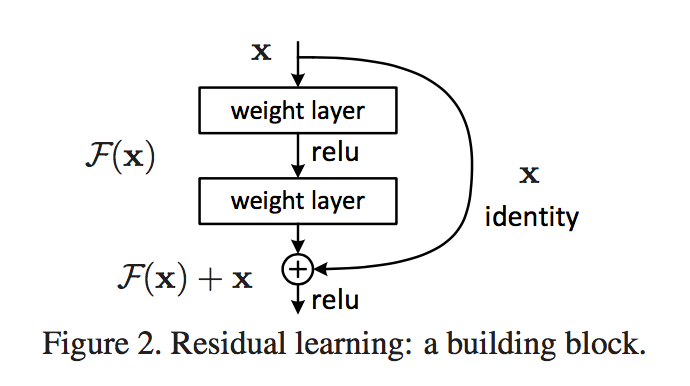
创新之处在于引入了残差网络结构,深度加大的同时,网络结构依然很简单,训练很快。
软件框架
主流框架比较
| 比较项 | Caffe | Torch | Theano | TensorFlow | MXNet |
|---|---|---|---|---|---|
| 主语言 | C++/cuda | C++/Lua/cuda | Python/c++/cuda | C++/cuda | C++/cuda |
| 从语言 | Python/Matlab | - | - | Python | Python/R/Julia/Go |
| 硬件 | CPU/GPU | CPU/GPU/FPGA | CPU/GPU | CPU/GPU/Mobile | CPU/GPU/Mobile |
| 分布式 | N | N | N | Y(未开源) | Y |
| 速度 | 快 | 快 | 中等 | 中等 | 快 |
| 灵活性 | 一般 | 好 | 好 | 好 | 好 |
| 文档 | 全面 | 全面 | 中等 | 中等 | 全面 |
| 适合模型 | CNN | CNN/RNN | CNN/RNN | CNN/RNN | CNN/RNN? |
| 操作系统 | 所有系统 | Linux, OSX | 所有系统 | Linux, OSX | 所有系统 |
| 命令式 | N | Y | N | N | Y |
| 声明式 | Y | N | Y | Y | Y |
| 接口 | protobuf | Lua | Python | C++/Python | Python/R/Julia/Go |
| 网络结构 | 分层方法 | 分层方法 | 符号张量图 | 符号张量图 | ? |
tensorflow
TensorFlow是Google开源的一款人工智能学习系统。为什么叫这个名字呢?Tensor的意思是张量,代表N维数组;Flow的意思是流,代表基于数据流图的计算。把N维数字从流图的一端流动到另一端的过程,就是人工智能神经网络进行分析和处理的过程。
话说在Android占领了移动端后,Google开源了TensorFlow,希望占领AI端。TF的特点是可以支持多种设备,大到GPU、CPU,小到平板和手机都可以跑起来TF。而且TF的使用很方便,几行代码就能开始跑模型,这让神经网络的入门变得非常简单。
|
|
TensorFlow有几个概念需要进行明确:
**1 图(Graph):**用来表示计算任务,也就我们要做的一些操作。
**2 会话(Session):**建立会话,此时会生成一张空图;在会话中添加节点和边,形成一张图,一个会话可以有多个图,通过执行这些图得到结果。如果把每个图看做一个车床,那会话就是一个车间,里面有若干个车床,用来把数据生产成结果。
**3 Tensor:**用来表示数据,是我们的原料。
**4 变量(Variable):**用来记录一些数据和状态,是我们的容器。
**5 feed和fetch:**可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据。相当于一些铲子,可以操作数据。
形象的比喻是:把会话看做车间,图看做车床,里面用Tensor做原料,变量做容器,feed和fetch做铲子,把数据加工成我们的结果。

Caffe
Caffe的全称是:Convolutional architecture forfast feature embedding,它是一个清晰、高效的深度学习框架,它是开源的,核心语言是C++,它支持命令行、Python和Matlab接口,它既可以在CPU上运行也可以在GPU上运行。它的license是BSD 2-Clause。Deep Learning比较流行的一个原因,主要是因为它能够自主地从数据上学到有用的feature。特别是对于一些不知道如何设计feature的场合,比如说图像和speech。
- Caffe是一款知名的深度学习框架,由加州大学伯克利分校的贾扬清博士于2013年在Github上发布。自那时起,Caffe在研究界和工业界都受到了极大的关注。Caffe的使用比较简单,代码易于扩展,运行速度得到了工业界的认可,同时还有十分成熟的社区。
- Caffe2是在2017年4月18日开幕的 F8 年度开发者大会上,Facebook 发布的一款全新的开源深度学习框架。
- Caffe2go是一个以开源项目Caffe2为基础、使用Unix理念构建的轻量级、模块化框架。其核心架构非常轻量化,而且可以附加多个模块。它是Facebook开发的一个可以在移动平台上实时获取、分析、处理像素的深度学习框架Caffe2Go。
pyTorch
PyTorch在学术研究者中很受欢迎,也是相对比较新的深度学习框架。Facebook人工智能研究组开发了PyTorch以应对一些在前任数据库Torch使用中遇到的问题。由于编程语言Lua的普及程度不高,Torch永远无法经历GoogleTensorFlow那样的迅猛发展。因此,PyTorch采用已经为许多研究人员、开发人员和数据科学家所熟悉的原始Python命令式编程风格。同时它还支持动态计算图,这一特性使得其对时间序列以及自然语言处理数据相关工作的研究人员和工程师很有吸引力。
theano
Theano是蒙特利尔大学蒙特利尔学习算法小组开发的一个开源项目。其一些最突出的特性包括GPU的透明使用,与NumPy紧密结合,高效的符号区分,速度/稳定性优化以及大量的单元测试。但是,2017年11月开始不再积极维护。原因在于Theano多年来推出的大部分创新技术现在已被其他框架所采用和完善。
PaddlePaddle
PaddlePaddle是百度研发的开源开放的深度学习平台,是国内最早开源、也是当前唯一一个功能完备的深度学习平台。依托百度业务场景的长期锤炼,PaddlePaddle有最全面的官方支持的工业级应用模型,涵盖自然语言处理、计算机视觉、推荐引擎等多个领域,并开放多个领先的预训练中文模型,以及多个在国际范围内取得竞赛冠军的算法模型。
PaddlePaddle同时支持稠密参数和稀疏参数场景的超大规模深度学习并行训练,支持千亿规模参数、数百个几点的高效并行训练,也是最早提供如此强大的深度学习并行技术的深度学习框架。PaddlePaddle拥有强大的多端部署能力,支持服务器端、移动端等多种异构硬件设备的高速推理,预测性能有显著优势。目前PaddlePaddle已经实现了API的稳定和向后兼容,具有完善的中英双语使用文档,形成了易学易用、简洁高效的技术特色。
PaddlePaddle3.0版本升级为全面的深度学习开发套件,除了核心框架,还开放了VisualDL、PARL、AutoDL、EasyDL、AIStudio等一整套的深度学习工具组件和服务平台,更好地满足不同层次的深度学习开发者的开发需求,具备了强大支持工业级应用的能力,已经被中国企业广泛使用,也拥有了活跃的开发者社区生态。
MXNet
MXNet的主要作者是李沐,最早就是几个人抱着纯粹对技术和开发的热情做起来的,如今成了亚马逊的官方框架,有着非常好的分布式支持,而且性能特别好,占用显存低,同时其开发的语言接口不仅仅有Python和C++,还有R,Matlab,Scala,JavaScript,等等,可以说能够满足使用任何语言的人。但是MXNet的缺点也很明显,教程不够完善,使用的人不多导致社区不大,同时每年很少有比赛和论文是基于MXNet实现的,这就使得MXNet的推广力度和知名度不高。
TensorFlow例子
https://blog.csdn.net/Sparta_117/article/details/66965760
lenet手写体识别
|
|
测试程序:加载手写图片,处理成28X28大小,再送入进行识别
|
|
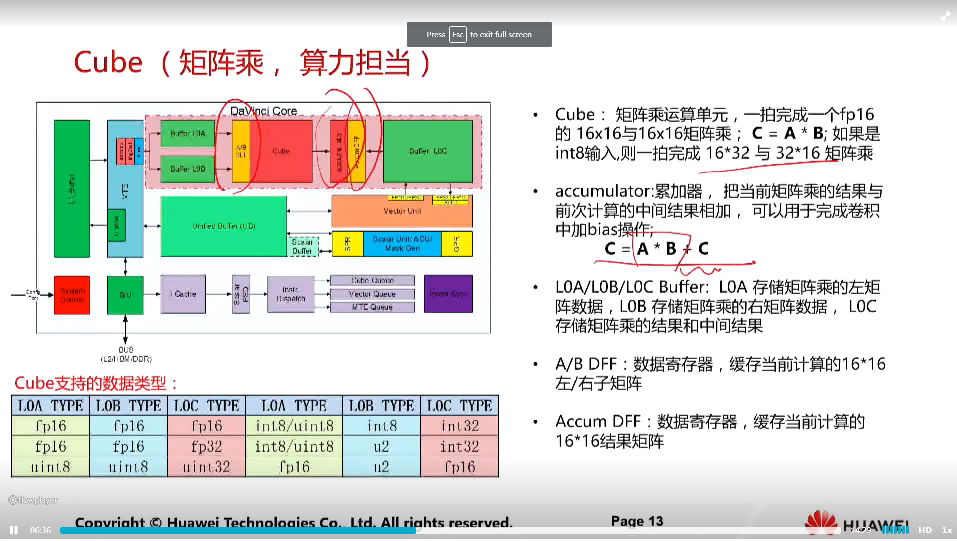
昇腾910/310
cube单元一个时钟周期可以计算一个16X16的矩阵与16X16的矩阵相乘
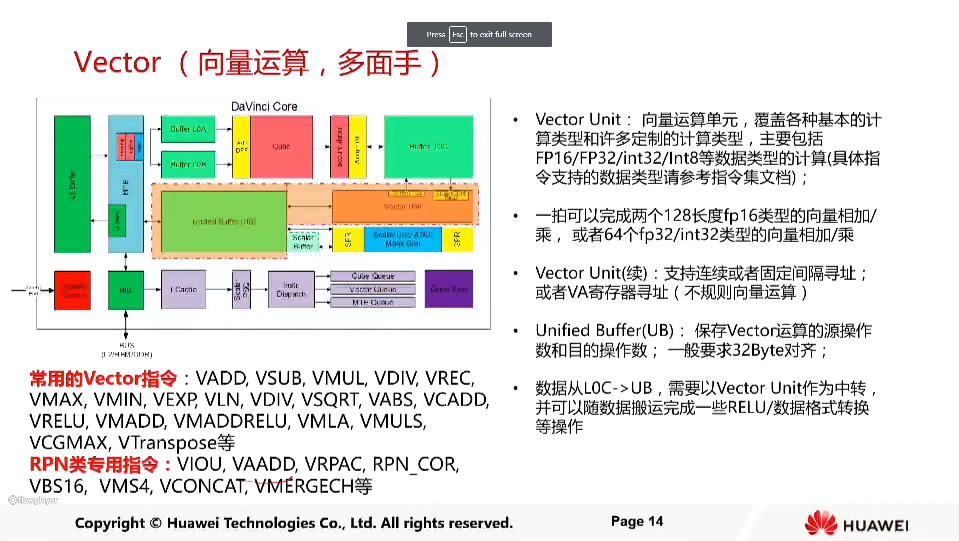
vector单元可以一个周期计算128个fp16类型向量相加/乘,或者64个fp32/int32类型向量的相加/乘
速查表
数据科学速查表: https://www.datacamp.com/community/tutorials/python-data-science-cheat-sheet-basics
数据整理速查表: https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf
数据整理: https://en.wikipedia.org/wiki/Data_wrangling
Keras速查表: https://www.datacamp.com/community/blog/keras-cheat-sheet#gs.DRKeNMs
Keras: https://en.wikipedia.org/wiki/Keras
机器学习速查表: https://ai.icymi.email/new-machinelearning-cheat-sheet-by-emily-barry-abdsc/
机器学习速查表: https://docs.microsoft.com/en-in/azure/machine-learning/machine-learning-algorithm-cheat-sheet
机器学习速查表: http://peekaboo-vision.blogspot.com/2013/01/machine-learning-cheat-sheet-for-scikit.html
Matplotlib速查表: https://www.datacamp.com/community/blog/python-matplotlib-cheat-sheet#gs.uEKySpY
Matpotlib: https://en.wikipedia.org/wiki/Matplotlib
神经网络速查表: http://www.asimovinstitute.org/neural-network-zoo/
神经网络图速查表: http://www.asimovinstitute.org/blog/
神经网络: https://www.quora.com/Where-can-find-a-cheat-sheet-for-neural-network
Numpy速查表: https://www.datacamp.com/community/blog/python-numpy-cheat-sheet#gs.AK5ZBgE
NumPy: https://en.wikipedia.org/wiki/NumPy
Pandas速查表: https://www.datacamp.com/community/blog/python-pandas-cheat-sheet#gs.oundfxM
Pandas: https://en.wikipedia.org/wiki/Pandas_(software)
Pandas速查表: https://www.datacamp.com/community/blog/pandas-cheat-sheet-python#gs.HPFoRIc
Scikit速查表: https://www.datacamp.com/community/blog/scikit-learn-cheat-sheet
Scikit-learn: https://en.wikipedia.org/wiki/Scikit-learn
Scikit-learn速查表: http://peekaboo-vision.blogspot.com/2013/01/machine-learning-cheat-sheet-for-scikit.html
Scipy速查表: https://www.datacamp.com/community/blog/python-scipy-cheat-sheet#gs.JDSg3OI
SciPy: https://en.wikipedia.org/wiki/SciPy
TesorFlow速查表: https://www.altoros.com/tensorflow-cheat-sheet.html
文章作者 carter2005
上次更新 2019-12-11