AI加速方法

文章目录
指令集优化
指令集是指CPU能执行的所有指令的集合,每一指令对应一种操作,任何程序最终要编译成一条条指令才能让CPU识别并执行。CPU依靠指令来计算和控制系统,所以指令强弱是衡量CPU性能的重要指标,指令集也成为提高CPU效率的有效工具。
CPU都有一个基本的指令集,比如说目前英特尔和AMD的绝大部分处理器都使用的是X86指令集,因为它们都源自于X86架构。但无论CPU有多快,X86指令也只能一次处理一个数据,这样效率就很低下,毕竟在很多应用中,数据都是成组出现的,比如一个点的坐标(XYZ)和颜色(RGB)、多声道音频等。为了提高CPU在某些方面的性能,就必须增加一些特殊的指令满足时代进步的需求,这些新增的指令就构成了扩展指令集。该指令集采用单指令多数据(single instruction multiple data,简称 SIMD)扩展技术。
指令集查询网站:https://software.intel.com/sites/landingpage/IntrinsicsGuide/
汇编
最接近硬件的语言
MMX
MMX是由英特尔开发的一种**SIMD**多媒体指令集,共有57条指令。它于1996年集成在英特尔奔腾(Pentium)MMX处理器上,以提高其多媒体数据的处理能力。
其优点是增加了處理器關於多媒体方面的处理能力,缺点是占用浮点数寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名)以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。AMD在此基础上发展出3D Now!指令集。
SSE
**SSE(Streaming SIMD Extensions)**是英特尔在AMD的3D Now!发布一年之后,在其计算机芯片Pentium III中引入的指令集,是繼MMX的擴充指令集。SSE指令集提供了70條新指令。AMD后来在Athlon XP中加入了对这个新指令集的支持。
SSE加入新的8個128位元暫存器(XMM0~XMM7)。而AMD發表的x86-64延伸架構(又稱AMD64)再加入額外8個暫存器。除此之外還有一個新的32位元的控制/狀態暫存器(MXCSR)。不過只能在64位元的模式下才能使用額外8個暫存器。
SSE(Streaming SIMD Extensions,流式单指令多数据扩展)指令集是1999年英特尔在Pentium III处理器中率先推出的,并将矢量处理能力从64位扩展到了128位。在Willamette核心的Pentium 4中英特尔又将扩展指令集升级到SSE2(2000年),而SSE3指令集(2004年)是从Prescott核心的Pentium 4开始出现。 SSE4(2007年)指令集是自SSE以来最大的一次指令集扩展,它实际上分成Penryn中出现的SSE4.1和Nehalem中出现的SSE4.2,其中SSE4.1占据了大部分的指令,共有47条,Nehalem中的SSE4指令集更新很少,只有7条指令,这样一共有54条指令,称为SSE4.2。
AVX
2007年8月,AMD抢先宣布了SSE5指令集(SSE到SSE4均为英特尔出品),英特尔当即黑脸表示不支持SSE5,转而在2008年3月宣布Sandy Bridge微架构将引入全新的AVX指令集,同年4月英特尔公布AVX指令集规范,随后开始不断进行更新,业界普遍认为支持AVX指令集是Sandy Bridge最重要的进步,没有之一。 AVX(Advanced Vector Extensions,高级矢量扩展)指令集借鉴了一些AMD SSE5的设计思路,进行扩展和加强,形成一套新一代的完整SIMD指令集规范。
AVX高级矢量扩展,在SSE的基础上又把寄存器大小扩展为256bit。这次AVX将所有16个128位XMM寄存器扩充为256位的YMM寄存器,从而支持256位的矢量计算。理想状态下,浮点性能最高能达到前代的2倍水平。同时所有的SSE/SSE2/SSE3/SSSE3/SSE4指令是被AVX全面兼容的(AVX不兼容MMX),因此实际操作的是YMM寄存器的低128位,在这一点上与原来的SSE系列指令集无异。
-
支持256位矢量计算,浮点性能最大提升2倍
-
增强的数据重排,更有效存取数据
-
支持3操作数和4操作数,在矢量和标量代码中能更好使用寄存器
-
支持灵活的不对齐内存地址访问
-
支持灵活的扩展性强的VEX编码方式,可减少代码
AVX2指令集将大多数整数命令操作扩展到256位,并引入了熔合乘法累积(FMA)运算。AVX-512则使用新的EVEX前缀编码将AVX指令进一步扩展到512位。Intel Xeon Scalable處理器支援AVX-512。
NEON
NEON是一种SIMD(Single Instruction Multiple Data)指令,也就是说,NEON可以把若干源(source)操作数(operand)打包放到一个源寄存器中,对他们执行相同的操作,产生若干目的(dest)操作数,这种方式也叫向量化(vectorization)。
可能你对这个描述还不够清晰,简单来说,就是:NEON指令优化的精髓就在于同时在不同通道内进行并行运算。通常可用于图像等矩阵数据的循环优化。
更简单的说,就是,将Neon寄存器分为多个通道,每个通道存储一个数据。一条对Neon寄存器的计算指令,实际上,是对各通道的数据分别的计算指令。即寄存器位宽,直接影响到数据的通道数。
例如:在ARMv7的NEON unit中,register file总大小是1024-bit,可以划分为16个128-bit的Q-register(Quadword register)或者32个64-bit的D-register(Dualword register),也就是说,最长的寄存器位宽是128-bit。那么,假设我们采用32-bit单精度浮点数float来做浮点运算,那么可以把最多128/32=4个浮点数打包放到Q-register中做运算,即4个4个参与计算,从而提高吞吐量,减少loop次数。
neon指令集列表:https://gcc.gnu.org/onlinedocs/gcc-4.7.4/gcc/ARM-NEON-Intrinsics.html#ARM-NEON-Intrinsics
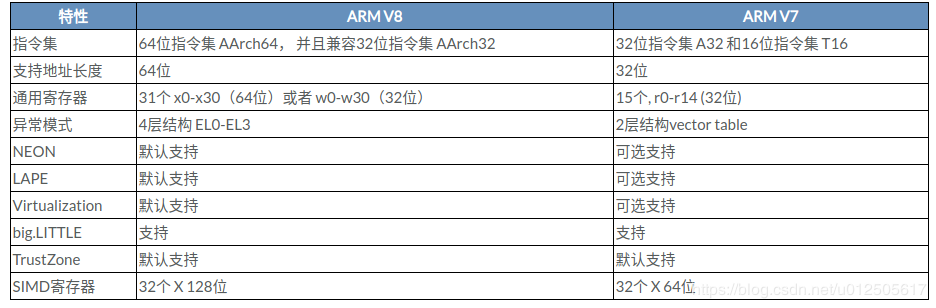
ARMv7 与 ARMv8的区别
指令集优化例子
汇编
|
|
neon
|
|
SSE
|
|
|
|
avx
|
|
内存布局
减少缓存miss,提升处理效率。对内存的重新组织(Repacking)可以改进高速缓存命中率,从而提高性能。但是这种重新组织也是有开销的。
计算核中最小的计算单元处理的是两个 4×4 矩阵相乘。传统的方法由于 𝐾 可能很大,需要对输入内存进行重新组织,防止相邻的访存引起高速缓存冲突
quantization
量化将网络中主要算子(卷积)由原先的浮点计算转成低精度的Int8计算,减少模型大小并提升性能。
编译MNN时开启MNN_BUILD_QUANTOOLS宏,即开启量化工具的编译。
卷积优化
im2col
https://www.jianshu.com/p/4907e6c93452
空间换时间方案,重复放数据,提高cache命中率,以此提高运行速度,但比较浪费内存
im2col 是计算机视觉领域中将图片的不同通道(channel)转换成矩阵的列(column)的计算过程。Caffe 在计算卷积时,首先用 im2col 将输入的三维数据转换成二维矩阵,使得卷积计算可表示成两个二维矩阵相乘,从而充分利用已经优化好的 GEMM 库来为各个平台加速卷积计算。
图十二是卷积的 im2col 过程的示例。随着卷积过滤器在输入上滑动,将被使用的那部分输入展开成一行大小为 𝐼𝐶×𝐾𝐻×𝐾𝑊 的向量。在滑动结束后,则得到特征矩阵 (𝐻×𝑊)×(𝐼𝐶×𝐾𝐻×𝐾𝑊) 。将过滤器展开成 (𝑂𝐶)×(𝐼𝐶×𝐾𝐻×𝐾𝑊) 的矩阵,那么卷积即可表示成这两个矩阵相乘的结果(特征矩阵要进行转置操作)。

Winograd
https://arxiv.org/pdf/1509.09308.pdf
对于现代的CPU,加减乘除都可以在一个指令周期内完成,这种单纯减少乘法的变换(加法会增多),究竟有多少的价值,有待商榷??论文测试系统是在GPU上实现的,GPU算乘法确实比加法要慢一些,比较适合本算法
https://www.cnblogs.com/shine-lee/p/10906535.html

fft
对于尺寸较大的卷积核,可以先fft变换为频域,相加后再反变换回来加速。
矩阵相乘 - strassen算法
典型矩阵乘法的复杂度是Θ(n^3),采用分治的思想,可以降为Θ(nlog7) =Θ (n2.81)

矩阵乘法中采用分治法,第一感觉上应该能够有效的提高算法的效率。如上图所示分治法方案,以及对该算法的效率分析。有图可知,算法效率是Θ(n^3)。算法效率并没有提高。
鉴于上面的分治法方案无法有效提高算法的效率,要想提高算法效率,由主定理方法可知必须想办法将2中递归式中的系数8减少。Strassen提出了一种将系数减少到7的分治法方案,如下图所示。

效率分析如下:

性能分析
| 矩阵大小 | 朴素矩阵算法(秒) | Strassen算法(秒) |
|---|---|---|
| 32 | 0.003 | 0.003 |
| 64 | 0.004 | 0.004 |
| 128 | 0.021 | 0.071 |
| 256 | 0.09 | 0.854 |
| 512 | 0.782 | 6.408 |
| 1024 | 8.908 | 52.391 |
可以发现:可以看到使用Strassen算法时,耗时不但没有减少,反而剧烈增多,在n=512时计算时间就无法忍受,效果没有朴素矩阵算法好。网上查阅资料,现罗列如下:
1)采用Strassen算法作递归运算,需要创建大量的动态二维数组,其中分配堆内存空间将占用大量计算时间,从而掩盖了Strassen算法的优势。
2)于是对Strassen算法做出改进,设定一个界限。当n<界限时,使用普通法计算矩阵,而不继续分治递归。需要合理设置界限,不同环境(硬件配置)下界限不同。
3)矩阵乘法一般意义上还是选择的是朴素的方法,只有当矩阵变稠密,而且矩阵的阶数很大时,才会考虑使用Strassen算法。
GPU加速
本质上是类似的,都是GPU计算方案,只是底层API存在差异。
ios/mac osx:metal
opencl/opengl/vulken:android,linux,windows
opengl
|
|
文章作者 carter2005
上次更新 2020-01-02