简介

MNN是一个轻量级的深度神经网络推理引擎,在端侧加载深度神经网络模型进行推理预测。目前,MNN已经在阿里巴巴的手机淘宝、手机天猫、优酷等20多个App中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等场景。此外,IoT等场景下也有若干应用。
特点
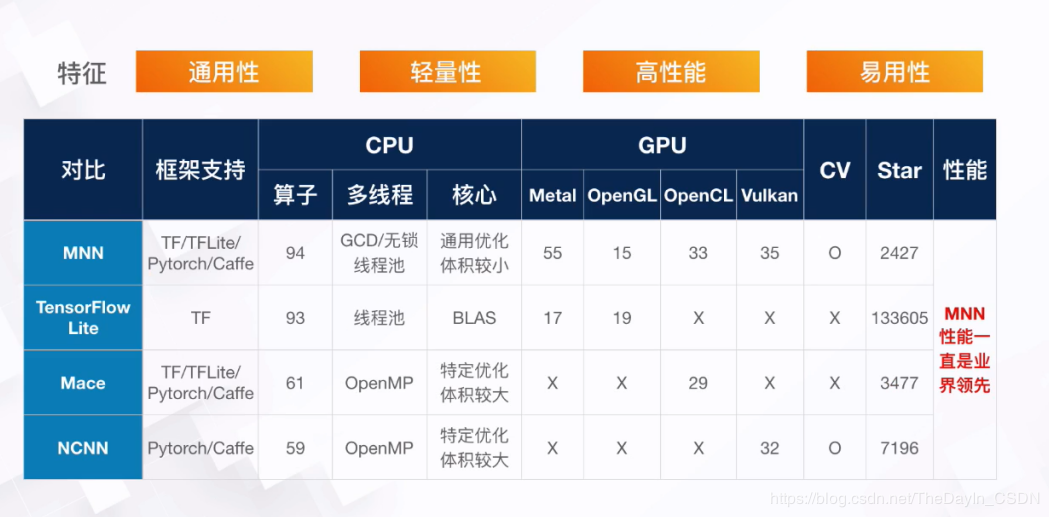
轻量性
- 针对端侧设备特点深度定制和裁剪,无任何依赖,可以方便地部署到移动设备和各种嵌入式设备中。
- iOS平台:armv7+arm64静态库大小5MB左右,链接生成可执行文件增加大小620KB左右,metallib文件600KB左右。
- Android平台:so大小400KB左右,OpenCL库400KB左右,Vulkan库400KB左右。
通用性
- 支持
Tensorflow、Caffe、ONNX等主流模型文件格式,支持CNN、RNN、GAN等常用网络。
- 支持86个
TensorflowOp、34个CaffeOp;各计算设备支持的MNN Op数:CPU 71个,Metal 55个,OpenCL 29个,Vulkan 31个。
- 支持iOS 8.0+、Android 4.3+和具有POSIX接口的嵌入式设备。
- 支持异构设备混合计算,目前支持CPU和GPU,可以动态导入GPU Op插件,替代CPU Op的实现。
高性能
- 不依赖任何第三方计算库,依靠大量手写汇编实现核心运算,充分发挥ARM CPU的算力。
- iOS设备上可以开启GPU加速(Metal),常用模型上快于苹果原生的CoreML。
- Android上提供了
OpenCL、Vulkan、OpenGL三套方案,尽可能多地满足设备需求,针对主流GPU(Adreno和Mali)做了深度调优。
- 卷积、转置卷积算法高效稳定,对于任意形状的卷积均能高效运行,广泛运用了 Winograd 卷积算法,对3x3 -> 7x7之类的对称卷积有高效的实现。
- 针对ARM v8.2的新架构额外作了优化,新设备可利用半精度计算的特性进一步提速。
易用性
- 有高效的图像处理模块,覆盖常见的形变、转换等需求,一般情况下,无需额外引入libyuv或opencv库处理图像。
- 支持回调机制,可以在网络运行中插入回调,提取数据或者控制运行走向。
- 支持只运行网络中的一部分,或者指定CPU和GPU间并行运行。
架构
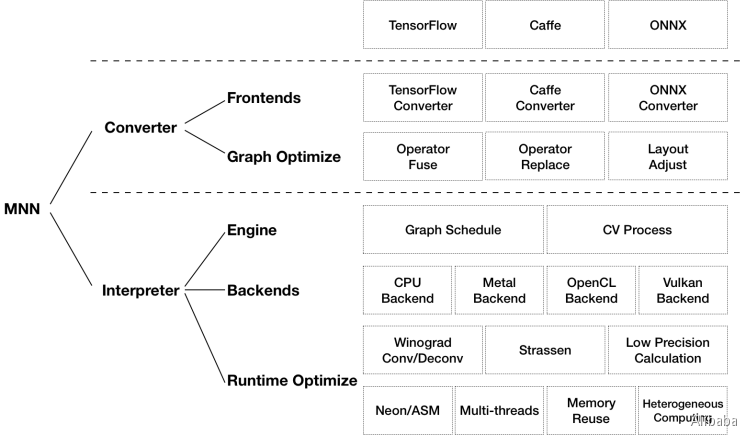
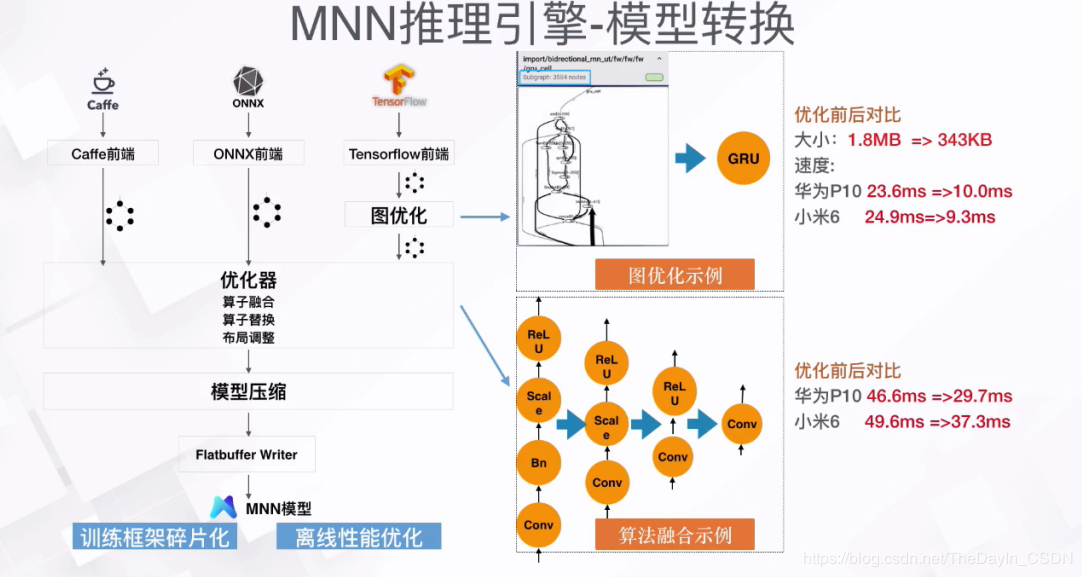
MNN可以分为Converter和Interpreter两部分。
Converter由Frontends和Graph Optimize构成。前者负责支持不同的训练框架,MNN当前支持Tensorflow(Lite)、Caffe和ONNX(PyTorch/MXNet的模型可先转为ONNX模型再转到MNN);后者通过算子融合、算子替代、布局调整等方式优化图。
Interpreter由Engine和Backends构成。前者负责模型的加载、计算图的调度;后者包含各计算设备下的内存分配、Op实现。在Engine和Backends中,MNN应用了多种优化方案,包括在卷积和反卷积中应用Winograd算法、在矩阵乘法中应用Strassen算法、低精度计算、Neon优化、手写汇编、多线程优化、内存复用、异构计算等。
用法
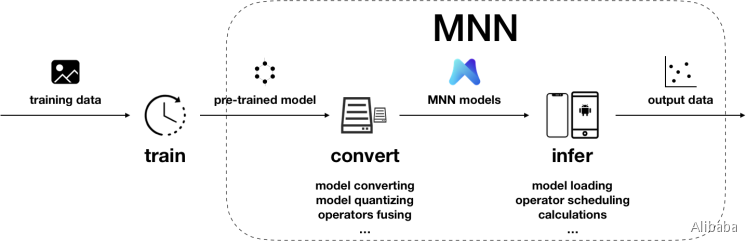
在训练框架上,根据训练数据训练出模型的阶段。虽然当前MNN也提供了训练模型的能力,但主要用于端侧训练或模型调优。在数据量较大时,依然建议使用成熟的训练框架,如TensorFlow、PyTorch等。除了自行训练外,也可以直接利用开源的预训练模型。
将其他训练框架模型转换为MNN模型的阶段。MNN当前支持Tensorflow(Lite)、Caffe和ONNX的模型转换。模型转换工具可以参考编译文档和使用说明。支持转换的算子,可以参考算子列表文档;在遇到不支持的算子时,可以尝试自定义算子,或在Github上给我们提交issue。
此外,模型打印工具可以用于输出模型结构,辅助调试。
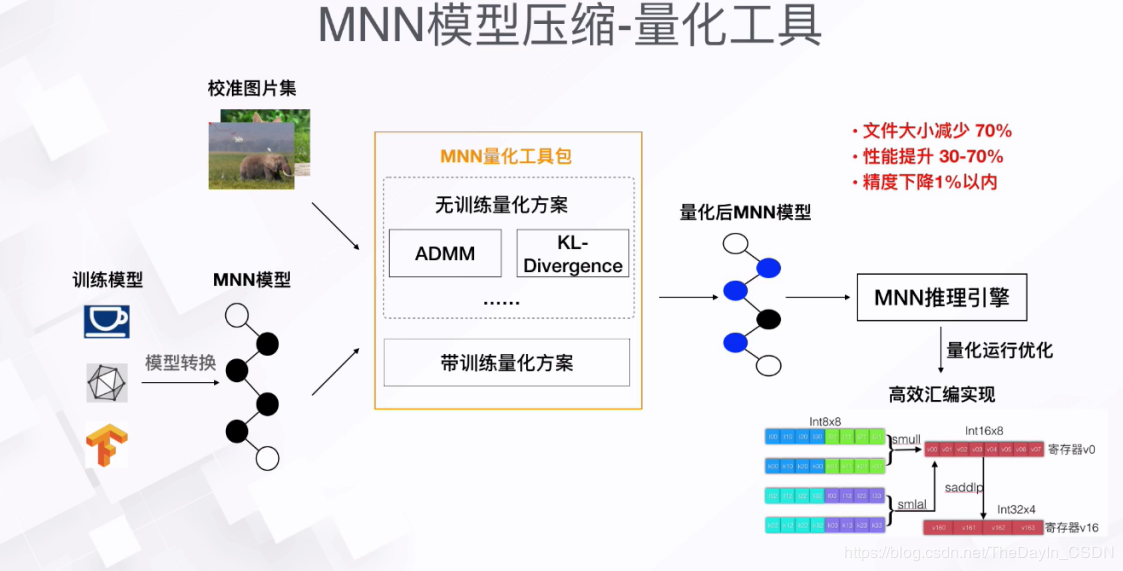
除模型转换外,MNN也提供了模型量化工具,可以对浮点模型进行量化压缩。
在端侧加载MNN模型进行推理的阶段。端侧运行库的编译请参考各平台的编译文档:iOS、Android、Linux/macOS/Ubuntu、Windows。我们提供了API接口文档,也详细说明了会话创建、数据输入、执行推理、数据输出相关的接口和参数。
自定义算子
1. 添加模型描述
若添加的算子不在MNN的算子列表中,需要添加模型描述
修改完模型描述后,需要调用generate脚本重新生成模型描述头文件。
添加算子类型
在schema/default/MNN.fbs文件的OpType列表里追加算子名称,如:
1
2
3
4
5
6
|
enum OpType : int {
AbsVal,
QuantizedAdd,
...
MyCustomOp
}
|
添加算子参数描述
如果算子不包含参数,则可以略过这一步。
首先,在schema/default/MNN.fbs文件的OpParameter列表里追加算子参数名称,如:
1
2
3
4
5
6
7
|
union OpParameter {
QuantizedAdd,
ArgMax,
AsString,
...
MyCustomOpParam
}
|
而后,添加参数描述。如果算子来自Caffe,选择CaffeOps.fbs;如果算子来自TensorFlow,就使用TensorflowOp.fbs。
1
2
3
4
5
6
7
8
9
|
table MyCustomOpParam {
padX:int;
padY:int;
kernelX:int;
kernelY:int;
strideX:int;
strideY:int;
dataType:DataType=DT_FLOAT;
}
|
2. 添加模型转换
用户可根据自己使用的框架,选择对应的模型转换模块去添加算子转换的支持
添加完模型转换后,需要重新cmake。
目前,MNN支持TensorFlow、TensorFlow Lite、Caffe和ONNX模型格式的转换。
TensorFlow模型转换
\1. 添加转换类
在tools/converter/source/tensorflow下添加MyCustomOpTf.cpp。可以直接声明转换类,也可以利用宏定义简化代码。
直接声明示例:
1
2
3
4
5
6
7
8
|
class MyCustomOpTf : public tfOpConverter {
public:
virtual void run(MNN::OpT *dstOp, TmpNode *srcNode, TmpGraph *tempGraph);
MyCustomOpTf() {}
virtual ~MyCustomOpTf() {}
virtual MNN::OpType opType();
virtual MNN::OpParameter type();
}
|
等效宏定义示例:
1
|
DECLARE_OP_CONVERTER(MyCustomOpTf);
|
需要实现run、析构、opType和type函数。其中,run函数用于解析模型的proto文件得到参数,然后赋值给flatbuffer自定义参数。参数srcNode保存有输入输出节点信息,可以根据输入输出节点在tempGraph中找到TmpNode。调用函数find_attr_value(const tensorflow::NodeDef& node, const char* key, tensorflow::AttrValue& value)获得对应参数的值。
注册转换类:
1
|
REGISTER_CONVERTER(MyCustomOpTf, MyCustomOp);
|
\2. 添加映射
在OpMapper.hpp中添加相应的TensorFlow Op名字到MNN Op名字的映射:
1
2
|
{"OpName1", MNN::OpType_MyCustomOp},
{"OpName2", MNN::OpType_MyCustomOp},
|
\3. 处理Op附带的Const
如果Const不作为此Op的参数,而是看成一个单独的Op,可以忽略此步骤;如果Op要把Const当成参数,要在文件TmpGraph.cpp里修改函数_genMinGraph(),把相应Const节点的isCovered属性设置为true。
TensorFlow Lite模型转换
\1. 添加转换类
在tools/converter/source/tflite下添加MyCustomOpTflite.cpp。
宏定义示例:
1
|
DECLARE_OP_COVERTER(MyCustomOpTflite);
|
需要实现函数:
1
2
3
4
5
6
7
8
|
MyCustomOpTflite::opType(bool quantizedModel);
MyCustomOpTflite::type(bool quantizedModel);
MyCustomOpTflite::run(MNN::OpT *dstOp,
const std::unique_ptr<tflite::OperatorT> &tfliteOp,
const std::vector<std::unique_ptr<tflite::TensorT> > &tfliteTensors,
const std::vector<std::unique_ptr<tflite::BufferT> > &tfliteModelBuffer,
const std::vector<std::unique_ptr<tflite::OperatorCodeT> > &tfliteOpSet,
bool quantizedModel)
|
其中,run函数相比TensorFlow的版本,多一个quantizedModel参数。若qu![img]()
antizedModel为true,则模型为量化模型,需转为相应的量化Op;若为false,转为浮点Op。在run函数中需要设置输入、输出tensor的index:
1
2
3
4
5
|
// set input output index
dstOp->inputIndexes.resize(1);
dstOp->outputIndexes.resize(1);
dstOp->inputIndexes[0] = tfliteOp->inputs[0];
dstOp->outputIndexes[0] = tfliteOp->outputs[0];
|
注册转换类:
1
2
|
using namespace tflite;
REGISTER_CONVERTER(MyCustomOpTflite, BuiltinOperator_OPName);
|
Caffe模型转换
\1. 添加转换类
在/tools/converter/source/caffe下添加MyCustomOp.cpp。
类声明示例:
1
2
3
4
5
6
7
8
9
10
|
class MyCustomOp : public OpConverter {
public:
virtual void run(MNN::OpT* dstOp,
const caffe::LayerParameter& parameters,
const caffe::LayerParameter& weight);
MyCustomOp() {}
virtual ~MyCustomOp() {}
virtual MNN::OpType opType();
virtual MNN::OpParameter type();
};
|
实现run、opType、type函数,在run函数中解析caffe参数得到具体参数。其中参数parameters保存有Op的参数信息,weight保存有卷积、BN等数据参数。
注册转换类:
1
|
static OpConverterRegister<MyCustomOp> a("MyCustomOp");
|
ONNX模型转换
\1. 添加转换类
在/tools/converter/source/onnx下添加MyCustomOpOnnx.cpp。
类声明示例:
1
|
DECLARE_OP_CONVERTER(MyCustomOpOnnx);
|
需要实现函数:
1
2
3
4
5
|
MNN::OpType MyCustomOpOnnx::opType();
MNN::OpParameter MyCustomOpOnnx::type();
void MyCustomOpOnnx::run(MNN::OpT* dstOp,
const onnx::NodeProto* onnxNode,
std::vector<const onnx::TensorProto*> initializers);
|
run函数中,onnxNode即onnx原始节点信息,权重等数据信息需从initializers取。
注册转换类:
1
|
REGISTER_CONVERTER(MyCustomOpOnnx, MyCustomOp);
|
3. 添加维度计算
如果该Op的输出Tensor大小与第1个输入Tensor一致,并且不需要分析FLOPS,可以跳过这步。
添加完形状计算代码后,需要重新cmake。
\1. 添加计算类
在/source/shape下添加ShapeMyCustomOp.cpp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class MyCustomOpSizeComputer : public SizeComputer {
public:
virtual bool onComputeSize(const MNN::Op* op, const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs) const override {
// set tensor->buffer.type
// .dimensions
// .dim[x].extent
// .dim[x].stride
// .dim[x].flag
return true;
}
virtual float onComputeFlops(const MNN::Op* op,
const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs) const {
return flops_for_calc_output_from_input;
}
};
|
在onComputeSize函数中,根据输入tensor的维度信息,计算输出tensor的维度信息,并设置输出tensor的数据类型。计算完成后返回true;若输入维度信息未知返回false。
在onComputeFlops函数中,根据输入、输出tensor的维度信息,返回总计算量。
注册计算类:
1
|
REGISTER_SHAPE(MyCustomOpSizeComputer, OpType_MyCustomOp);
|
4. 添加实现
添加完算子实现后,需要重新cmake。
添加CPU实现
在source/backend/CPU目录下添加CPUMyCustomOp.hpp、CPUMyCustomOp.cpp。
\1. 实现类声明
1
2
3
4
5
6
7
8
9
|
class CPUMyCustomOp : public Execution {
public:
// 若执行onExecute需要使用缓存,在此函数中申请,若无可不声明
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
// 具体的Op执行函数
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
|
\2. 实现onResize和onExecute
在onResize中,调用backend()->onAcquireBuffer(&mCache, Backend::DYNAMIC)进行缓存的申请,调用backend()->onReleaseBuffer(&mCache, Backend::DYNAMIC)回收缓存。释放后的内存可以被复用。
在onExecute中,做必要的输入的检查,有利于提前发现问题。若执行完毕正确返回NO_ERROR。
\3. 注册实现类
1
2
3
4
5
6
7
8
9
10
|
class CPUMyCustomOpCreator : public CPUBackend::Creator {
public:
virtual Execution *onCreate(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs,
const MNN::Op *op,
Backend *backend) const override {
return new CPUMyCustomOp(backend);
}
};
REGISTER_CPU_OP_CREATOR(CPUMyCustomOpCreator, OpType_MyCustomOp);
|
\1. 添加Shader
在source/backend/Metal目录下添加MetalMyCustomOp.metal,并添加进Xcode工程。metal可以参考目录下已有实现。
\2. 实现类声明
在source/backend/Metal目录下添加MetalMyCustomOp.hpp和MetalMyCustomOp.cpp,并添加进Xcode工程:
1
2
3
4
5
6
7
|
class MetalMyCustomOp : public Execution {
public:
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
|
\3. 实现onResize和onExecute
不同于CPU Tensor将数据存储在host指针中,Metal数据指针存放在deviceId中,deviceId上存储的是id<MTLBuffer>:
1
|
auto buffer = (__bridge id<MTLBuffer>)(void *)tensor->deviceId();
|
Metal Op的特定参数等可以通过id<MTLBuffer>存储。buffer数据类型可以与tensor不同,buffer甚至可以混合多种数据类型,只需保证创建时指定了正确的长度即可。例如:
1
2
3
4
5
|
auto buffer = [context newDeviceBuffer:2 * sizeof(int) + 2 * sizeof(__fp16) access:CPUWriteOnly];
((__fp16 *)buffer.contents)[0] = mAlpha / mLocalSize; // alpha
((__fp16 *)buffer.contents)[1] = mBeta; // beta
((int *)buffer.contents)[1] = mLocalSize; // local size
((int *)buffer.contents)[2] = inputs[0]->channel(); // channel
|
在创建buffer时,需要指定访问控制权限。目前共有三种权限:
-
CPUReadWrite,数据在CPU/GPU间共享存储,一般用于device buffer;CPUWriteOnly,数据通过CPU写入后不再读取,一般用于参数buffer;CPUTransparent,数据只在GPU中,一般用于heap buffer;
MNNMetalContext在创建buffer上,有两套相近的接口,区别只在数据的生命周期上:
-
- device占用的内存在单次推理过程中都不会被复用;
- 而heap占用的内存,在调用
-[MNNMetalContext releaseHeapBuffer:]之后,可以被其他Op复用;
一般而言,heap只会与CPUTransparent一起使用。heap实际只在iOS 10+上有效,iOS 9-上会回退到device上。
使用Metal时,如非特殊情况,禁止自行创建device和library。加载library、编译function都是耗时行为,MNNMetalContext上做了必要的缓存优化。通过context执行Metal的示例如下:
1
2
3
4
5
6
7
8
9
|
auto context = (__bridge MNNMetalContext *)backend->context();
auto kernel = /* metal kernel name NSString */;
auto encoder = [context encoder];
auto bandwidth = [context load:kernel encoder:encoder];
/* encoder set buffer(s)/sampler(s) */
[context dispatchEncoder:encoder
threads:{x, y, z}
maxThreadsPerGroup:maxThreadsPerThreadgroup]; // recommended way to dispatch
[encoder endEncoding];
|
\4. 注册实现类
1
2
3
4
5
6
7
8
|
class MetalMyCustomOpCreator : public MetalBackend::Creator {
public:
virtual Execution *onCreate(const std::vector<Tensor *> &inputs,
const MNN::Op *op, Backend *backend) const {
return new MetalMyCustomOp(backend);
}
};
REGISTER_METAL_OP_CREATOR(MetalMyCustomOpCreator, OpType_MyCustomOp);
|
添加Vulkan实现
\1. 添加Shader
在source/backend/vulkan/execution/glsl![img]() 目录下添加具体的shader(*.comp)。若输入内存布局为
目录下添加具体的shader(*.comp)。若输入内存布局为NC4HW4,则按image实现,否则采用buffer实现。可以参考目录下已有实现。然后,执行makeshader.py脚本编译Shader。
\2. 实现类声明
在目录source/backend/vulkan/execution/下添加VulkanMyCustomOp.hpp和VulkanMyCustomOp.cpp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class VulkanMyCustomOp : public VulkanBasicExecution {
public:
VulkanMyCustomOp(const Op* op, Backend* bn);
virtual ~VulkanMyCustomOp();
ErrorCode onEncode(const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs,
const VulkanCommandPool::Buffer* cmdBuffer) override;
private:
// GPU Shader所需的参数
std::shared_ptr<VulkanBuffer> mConstBuffer;
// Pipeline
const VulkanPipeline* mPipeline;
// Layout Descriptor Set
std::shared_ptr<VulkanPipeline::DescriptorSet> mDescriptorSet;
};
|
\3. 实现
实现函数onEncode,首先需要做内存布局检查:若为NC4HW4,则Shader用image实现,否则用buffer。执行完毕返回NO_ERROR。
\4. 注册实现类
1
2
3
4
5
6
7
8
9
10
11
12
|
class VulkanMyCustomOpCreator : public VulkanBackend::Creator {
public:
virtual Execution* onCreate(const std::vector<Tensor*>& inputs,
const MNN::Op* op,
Backend* backend) const override {
return new VulkanMyCustomOp(op, backend);
}
};
static bool gResistor = []() {
VulkanBackend::addCreator(OpType_MyCustomOp, new VulkanMyCustomOpCreator);
return true;
}();
|
添加OpenCL实现
\1. 添加Kernel
在source/backend/opencl/execution/cl目录添加具体的kernel(*.cl)。目前feature map均使用image2d实现。可以参考目录下已有实现。然后执行opencl_codegen.py来生成kernel映射。
\2. 实现类声明
在目录source/backend/opencl/execution/下添加MyCustomOp.h和MyCustomOp.cpp:
1
2
3
4
5
6
7
8
|
template <typename T>
class MyCustomOp : public Execution {
public:
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
|
\3. 实现
实现函数onResize(可选)、onExecute。执行完毕返回NO_ERROR。
\4. 注册实现类
1
|
OpenCLCreatorRegister<TypedCreator<MyCustomOp<cl_data_t>>> __my_custom_op(OpType_MyCustomOp);
|
添加OpenGL实现
\1. 添加Shader
在source/backend/opengl/glsl下添加具体的shader(*.glsl),不用加文件头,feature map 均采用image3d表示。可以参考目录下已有实现。而后,在source/backend/opengl目录下执行makeshader.py。
\2. 添加Executor
在source/backend/opengl/execution/目录下添加GLMyCustomOp.h和GLMyCustomOp.cpp:
1
2
3
4
5
6
7
8
9
10
11
12
|
class GLMyCustomOp : public Execution {
public:
GLMyCustomOp(const std::vector<Tensor *> &inputs, const Op *op, Backend *bn);
virtual ~GLMyCustomOp();
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
private:
std::shared_ptr<GLProgram> mProgram;
};
|
\3. 实现
实现函数onResize(可选)、onExecute。执行完毕返回NO_ERROR。
\4. 注册实现类-
1
|
GLCreatorRegister<TypedCreator<GLMyCustomOp>> __my_custom_op(OpType_MyCustomOp);
|
矩阵相乘
原理
MNN的实现也是简单的按行数据并行处理。
矩阵乘法
矩阵乘法的目的是完成一个计算:C = A * B,其中A是h * k, B是k * w,所以C是h * w。
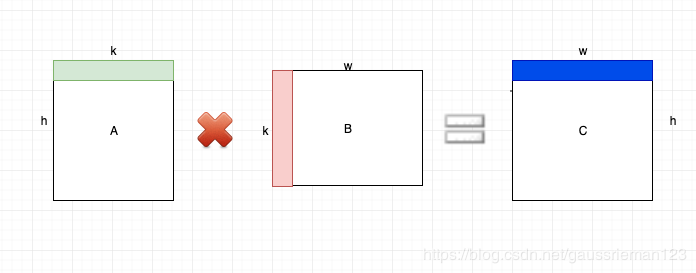
常用的方式是分行处理,对于C的第一行,可以按如下方式处理:
1
|
C(0,j) += A(0,i)*B(i,j)
|
对于行主序矩阵,每一行的数据是连续存储的,我们自然可以考虑使用SIMD指令,一次处理4个(假设是Float32)数据的相乘:
1
2
3
4
5
|
float32x4_t a0 = vdupq_n_f32(aLine[i]);
float32x4_t b0 = vld1q_f32(bLine);
float32x4_t sum0 = vdupq_n_f32(0.0);
sum0 = vmlaq_f32(sum0, a0, b0);
vst1q_f32(cLine, sum0);
|
需要注意的一点是,如果w不能被4整除,那么需要处理边界,逐个点进行计算并赋值:
1
|
C(0,j) += A(0,i) * B(i,j)
|
MNN实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
void Matrix::multi(Tensor* C, const Tensor* A, const Tensor* B) {
MNN_ASSERT(NULL != C);
MNN_ASSERT(NULL != B);
MNN_ASSERT(NULL != A);
MNN_ASSERT(2 == C->dimensions());
MNN_ASSERT(2 == B->dimensions());
MNN_ASSERT(2 == A->dimensions());
const auto a = A->host<float>();
const auto b = B->host<float>();
auto c = C->host<float>();
const int h = A->length(0);
const int k = A->length(1);
const int w = B->length(1);
const int aw = A->stride(0);
const int bw = B->stride(0);
const int cw = C->stride(0);
MNN_ASSERT(k == B->length(0));
int y = 0;
for (; y < h; ++y) {
int x = 0;
const auto aLine = a + y * aw;
auto cLine = c + y * cw;
#ifdef MNN_USE_NEON
// firstly, compute 16 together
for (; x <= w - 16; x += 16) {
auto bColumn = b + x;
float32x4_t sum0 = vdupq_n_f32(0.0);
float32x4_t sum1 = vdupq_n_f32(0.0);
float32x4_t sum2 = vdupq_n_f32(0.0);
float32x4_t sum3 = vdupq_n_f32(0.0);
for (int i = 0; i < k; ++i) {
const auto bLine = bColumn + i * bw;
float32x4_t a0 = vdupq_n_f32(aLine[i]);
float32x4_t b0 = vld1q_f32(bLine);
float32x4_t b1 = vld1q_f32(bLine + 4);
float32x4_t b2 = vld1q_f32(bLine + 8);
float32x4_t b3 = vld1q_f32(bLine + 12);
sum0 = vmlaq_f32(sum0, a0, b0);
sum1 = vmlaq_f32(sum1, a0, b1);
sum2 = vmlaq_f32(sum2, a0, b2);
sum3 = vmlaq_f32(sum3, a0, b3);
}
vst1q_f32(cLine + x, sum0);
vst1q_f32(cLine + x + 4, sum1);
vst1q_f32(cLine + x + 8, sum2);
vst1q_f32(cLine + x + 12, sum3);
}
// secondly, compute 4 together
for (; x <= w - 4; x += 4) {
auto bColumn = b + x;
float32x4_t sum = vdupq_n_f32(0.0);
for (int i = 0; i < k; ++i) {
const auto bLine = bColumn + i * bw;
float32x4_t a4 = vdupq_n_f32(aLine[i]);
float32x4_t b4 = vld1q_f32(bLine);
sum = vmlaq_f32(sum, a4, b4);
}
vst1q_f32(cLine + x, sum);
}
#endif
for (; x < w; ++x) {
auto bColumn = b + x;
float sum = 0.0f;
for (int i = 0; i < k; ++i) {
sum += aLine[i] * bColumn[i * bw];
}
cLine[x] = sum;
}
}
}
|
关键部分是MNN_USE_NEON宏包裹的部分,具体的思路,对输出矩阵C进行循环,因为是行主序(每一行连续存储),所以按行来进行计算,只不过它这里,先按16循环,可以利用流水线,提升效率,然后对于小于16的部分,先4个一组处理,对于小于4的边界部分,逐点处理。
source分析
| 内容 |
作用 |
| 3rd_party |
第三方工具 |
| benchmark |
性能测试工具 |
| cmake |
编译相关 |
| CMakeLists.txt |
编译相关 |
| demo |
demo |
| doc |
文档 |
| express |
|
| include |
头文件 |
| project |
android,ios,linux工程 |
| pymnn |
python包 |
| resource |
模型,图片等资源 |
| schema |
描述文件,编译相关 |
| source |
核心算法库 |
| test |
测试相关 |
| tools |
converter,quantization等工具 |
重点关注source目录,source下面有5个目录,分别为
| 目录 |
用途 |
| backend |
CPU,GPU加速后端 |
| core |
核心框架,backend,session,pipeline,execution,schedule等框架 |
| cv |
图像库,各种颜色格式,图像格式转换, |
| math |
matrix,vertex,wingored基本运算 |
| shape |
算子定义 |
backend
arm82
这个目录下面是arm处理器的优化cpu算子,包含1X1的卷积,矩阵优化汇编等几个优化实现。
cpu
通用的cpu后端实现,包含x86的asm,sse,avx等优化实现
GPU加速方案,api不一样
Interp算子
功能介绍
图像采样算法:https://blog.csdn.net/LanerGaming/article/details/49207435
重采样效果图:https://clouard.users.greyc.fr/Pantheon/experiments/rescaling/index-en.html
1、格式 VI = interpn(X1,X2,,…,Xn,V,Y1,Y2,…,Yn) %返回由参量X1,X2,…,Xn,V确定的n元函数V=V(X1,X2,…,Xn)在点(Y1,Y2,…,Yn)处的插值。参量Y1,Y2,…,Yn是同型的矩阵或向量。若Y1,Y2,…,Yn是向量,则可以是不同长度,不同方向(行或列)的向量。它们将通过命令ndgrid生成同型的矩阵,再作计算。若点(Y1,Y2,…,Yn)中有位于点(X1,X2,…,Xn)之外的点,则相应地返回特殊变量NaN。
2、VI = interpn(V,Y1,Y2,…,Yn) %缺省地,X1=1:size(V,1),X2=1:size(V,2),…,Xn=1:size(V,n),再按上面的情形计算。
3、VI = interpn(V,ntimes) %作ntimes次递归计算,在V的每两个元素之间插入它们的n维插值。这样,V的阶数将不断增加。interpn(V)等价于interpn(V,1)。
4、VI = interpn(…,method) %用指定的算法method计算:
bilinear: Bilinear interpolation. If ‘antialias’ is true, becomes a hat/tent filter function with radius 1 when downsampling.lanczos3: Lanczos kernel with radius 3. High-quality practical filter but may have some ringing especially on synthetic images.lanczos5: Lanczos kernel with radius 5. Very-high-quality filter but may have stronger ringing.bicubic: Cubic interpolant of Keys. Equivalent to Catmull-Rom kernel. Reasonably good quality and faster than Lanczos3Kernel, particularly when upsampling.gaussian: Gaussian kernel with radius 3, sigma = 1.5 / 3.0.nearest: Nearest neighbor interpolation. ‘antialias’ has no effect when used with nearest neighbor interpolation.area: Anti-aliased resampling with area interpolation. ‘antialias’ has no effect when used with area interpolation; it always anti-aliases.mitchellcubic: Mitchell-Netravali Cubic non-interpolating filter. For synthetic images (especially those lacking proper prefiltering), less ringing than Keys cubic kernel but less sharp.
mnn实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
|
ErrorCode CPUInterp::onExecute(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) {
auto &input = inputs[0]->buffer();
auto &output = outputs[0]->buffer();
if (mResizeType == 1) {
// Nearstneighbor
CPUReiseNearstneighborC4(input, output, mWidthScale, mHeightScale);
} else if (mResizeType == 2) {
// bilinear
CPUResizeBilinearC4(input, output, mWidthPosition.host<int>(), mWidthFactor.host<float>(),
mHeightPosition.host<int>(), mHeightFactor.host<float>(), mLineBuffer.host<float>(),
((CPUBackend *)backend())->threadNumber());
} else if (mResizeType == 3) {
// cubic
CPUResizeCubicC4(input, output);
} else {
return NOT_SUPPORT;
// not supported
}
return NO_ERROR;
}
void CPUResizeCommon::CPUReiseNearstneighborC4(halide_buffer_t& input, halide_buffer_t& output, float wScale,
float hScale) {
const int batches = input.dim[0].extent;
const int inputBatchSize = input.dim[0].stride;
const int outputBatchSize = output.dim[0].stride;
const int inW = input.dim[3].extent;
const int inH = input.dim[2].extent;
const int outW = output.dim[3].extent;
const int outH = output.dim[2].extent;
const float xScaling = wScale;
const float yScaling = hScale;
const int depthQuad = UP_DIV(input.dim[1].extent, 4);
AutoStorage<int> linePosition(outW);
auto _linePosition = linePosition.get();
for (int x = 0; x < outW; ++x) {
float src_x = x * xScaling;
int x1 = static_cast<int>(floor(src_x));
_linePosition[x] = CLAMP(x1, 0, inW - 1);
}
for (int b = 0; b < batches; ++b) {
MNN_CONCURRENCY_BEGIN(n, depthQuad) {
auto srcData =
reinterpret_cast<const float*>(input.host) + b * inputBatchSize + static_cast<int>(n) * 4 * inW * inH;
auto dstData =
reinterpret_cast<float*>(output.host) + b * outputBatchSize + static_cast<int>(n) * 4 * outW * outH;
for (int dy = 0; dy < outH; ++dy) {
float srcY = dy * yScaling;
const int y_ = CLAMP(static_cast<int>(floor(srcY)), 0, inH - 1);
auto srcDataLine = srcData + inW * 4 * y_;
auto dstDataLine = dstData + outW * 4 * dy;
for (int dx = 0; dx < outW; ++dx) {
::memcpy(dstDataLine + dx * 4, srcDataLine + _linePosition[dx] * 4, sizeof(float) * 4);
}
}
}
MNN_CONCURRENCY_END();
}
}
void CPUResizeCommon::CPUResizeBilinearC4(halide_buffer_t& input, halide_buffer_t& output, const int* widthPosition,
const float* widthFactor, const int* heightPosition,
const float* heightFactor, float* lineBuffer, int threadNumber) {
const int batches = input.dim[0].extent;
const int inputBatchSize = input.dim[0].stride;
const int outputBatchSize = output.dim[0].stride;
const int inW = input.dim[3].extent;
const int inH = input.dim[2].extent;
const int outW = output.dim[3].extent;
const int outH = output.dim[2].extent;
int depthQuad = UP_DIV(input.dim[1].extent, 4);
for (int b = 0; b < batches; ++b) {
auto threadFunction = [&](size_t tId) {
for (int n = (int)tId; n < depthQuad; n += threadNumber) {
auto _lineBuffer = lineBuffer + 2 * 4 * outW * tId;
auto _line0 = _lineBuffer + 4 * outW * 0;
auto _line1 = _lineBuffer + 4 * outW * 1;
int yUsed[2] = {0, 0};
int yCache[2] = {-1, -1};
float* yCacheLine[2] = {_line0, _line1};
float* const yCacheStorage[2] = {_line0, _line1};
auto bottomData =
reinterpret_cast<const float*>(input.host) + b * inputBatchSize + (int)n * 4 * inW * inH;
auto topData = reinterpret_cast<float*>(output.host) + b * outputBatchSize + (int)n * 4 * outW * outH;
for (int dy = 0; dy < outH; dy++) {
int yp[2];
yp[0] = heightPosition[2 * dy + 0];
yp[1] = heightPosition[2 * dy + 1];
// Search cache
for (int j = 0; j < 2; ++j) {
yUsed[j] = 0;
}
for (int j = 0; j < 2; ++j) {
int find = 0;
for (int k = 0; k < 2; ++k) {
if (yp[j] == yCache[k]) {
yUsed[k] = 1;
yCacheLine[j] = yCacheStorage[k];
find = 1;
break;
}
}
if (!find) {
const float* bottomY0 = bottomData + yp[j] * inW * 4;
for (int k = 0; k < 2; ++k) {
if (!yUsed[k]) {
yCache[k] = yp[j];
yUsed[k] = 1;
yCacheLine[j] = yCacheStorage[k];
CPUBilinearSampleC4(bottomY0, yCacheLine[j], widthPosition, widthFactor, outW);
break;
}
}
}
}
auto topY = topData + outW * 4 * dy;
// Sample Input
CPUBilinearLineC4(topY, yCacheLine[0], yCacheLine[1], &heightFactor[dy], outW);
}
}
};
MNN_CONCURRENCY_BEGIN(tId, threadNumber) {
threadFunction(tId);
}
MNN_CONCURRENCY_END();
}
}
void CPUResizeCommon::CPUResizeCubicC4(halide_buffer_t& input, halide_buffer_t& output) {
const int batches = input.dim[0].extent;
const int inBatchSize = input.dim[0].stride;
const int outBatchSize = output.dim[0].stride;
const int inW = input.dim[3].extent;
const int inH = input.dim[2].extent;
const int N = input.dim[1].extent;
const int outW = output.dim[3].extent;
const int outH = output.dim[2].extent;
const int depthQuad = UP_DIV(N, 4);
AutoStorage<int> linePosition(4 * outW);
AutoStorage<float> lineFactor(outW);
auto _linePosition = linePosition.get();
auto _lineFactor = lineFactor.get();
// Compute Line Position
for (int dx = 0; dx < outW; ++dx) {
float u = ((float)dx) / ((float)(outW - 1));
float x = u * inW - 0.5f;
int xInt = (int)x;
_lineFactor[dx] = (float)(x - floor(x));
_linePosition[4 * dx + 0] = CLAMP(xInt - 1, 0, inW - 1);
_linePosition[4 * dx + 1] = CLAMP(xInt + 0, 0, inW - 1);
_linePosition[4 * dx + 2] = CLAMP(xInt + 1, 0, inW - 1);
_linePosition[4 * dx + 3] = CLAMP(xInt + 2, 0, inW - 1);
}
for (int b = 0; b < batches; ++b) {
MNN_CONCURRENCY_BEGIN(n, depthQuad);
{
int yUsed[4] = {0, 0, 0, 0};
int yCache[4] = {-1, -1, -1, -1};
AutoStorage<float> lineBuffer(16 * outW);
auto _lineBuffer = lineBuffer.get();
auto _line0 = _lineBuffer + 4 * outW * 0;
auto _line1 = _lineBuffer + 4 * outW * 1;
auto _line2 = _lineBuffer + 4 * outW * 2;
auto _line3 = _lineBuffer + 4 * outW * 3;
float* yCacheLine[4] = {_line0, _line1, _line2, _line3};
float* const yCacheStorage[4] = {_line0, _line1, _line2, _line3};
auto bottomData = reinterpret_cast<const float*>(input.host) + b * inBatchSize + (int)n * 4 * inW * inH;
auto topData = reinterpret_cast<float*>(output.host) + b * outBatchSize + (int)n * 4 * outW * outH;
for (int dy = 0; dy < outH; dy++) {
float v = ((float)dy) / ((float)(outH - 1));
float y = v * inH - 0.5f;
int yInt = (int)y;
int yp[4];
yp[0] = CLAMP(yInt - 1, 0, inH - 1);
yp[1] = CLAMP(yInt, 0, inH - 1);
yp[2] = CLAMP(yInt + 1, 0, inH - 1);
yp[3] = CLAMP(yInt + 2, 0, inH - 1);
// Search cache
for (int j = 0; j < 4; ++j) {
yUsed[j] = 0;
}
for (int j = 0; j < 4; ++j) {
int find = 0;
for (int k = 0; k < 4; ++k) {
if (yp[j] == yCache[k]) {
yUsed[k] = 1;
yCacheLine[j] = yCacheStorage[k];
find = 1;
break;
}
}
if (!find) {
const float* bottomY0 = bottomData + yp[j] * inW * 4;
for (int k = 0; k < 4; ++k) {
if (!yUsed[k]) {
yCache[k] = yp[j];
yUsed[k] = 1;
yCacheLine[j] = yCacheStorage[k];
MNNCubicSampleC4(bottomY0, yCacheLine[j], _linePosition, _lineFactor, outW);
break;
}
}
}
}
// Sample Input
float yFract = (float)(y - floor(y));
auto topY = topData + outW * 4 * dy;
MNNCubicLineC4(topY, yCacheLine[0], yCacheLine[1], yCacheLine[2], yCacheLine[3], &yFract, outW);
}
}
MNN_CONCURRENCY_END();
}
}
|
broadcast分析
概念
对于shape匹配的tensor,运算可以自动扩展到每个元素,例如下面的操作
1
2
3
4
5
6
7
8
9
10
|
>>> import tensorflow as tf
>>> x=tf.constant([1,2,3,4,5,6,7,8,9],shape=[3,3])
>>> y=tf.constant([1,0,1])
>>> z=x+y
>>> print(z)
tf.Tensor(
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]], shape=(3, 3), dtype=int32)
>>>
|
广播允许我们执行隐藏的功能,这使代码更简单,并且提高了内存的使用效率,因为我们不需要再使用其他的操作。
机制
Broadcasting 机制的核心思想是普适性,即同一份数据能普遍适合于其他位置。在验证普适性之前,需要先将张量shape 靠右对齐,然后进行普适性判断:对于长度为1 的维度,默认这个数据普遍适合于当前维度的其他位置;对于不存在的维度,则在增加新维度后默认当前数据也是普适于新维度的,从而可以扩展为更多维度数、任意长度的张量形状。
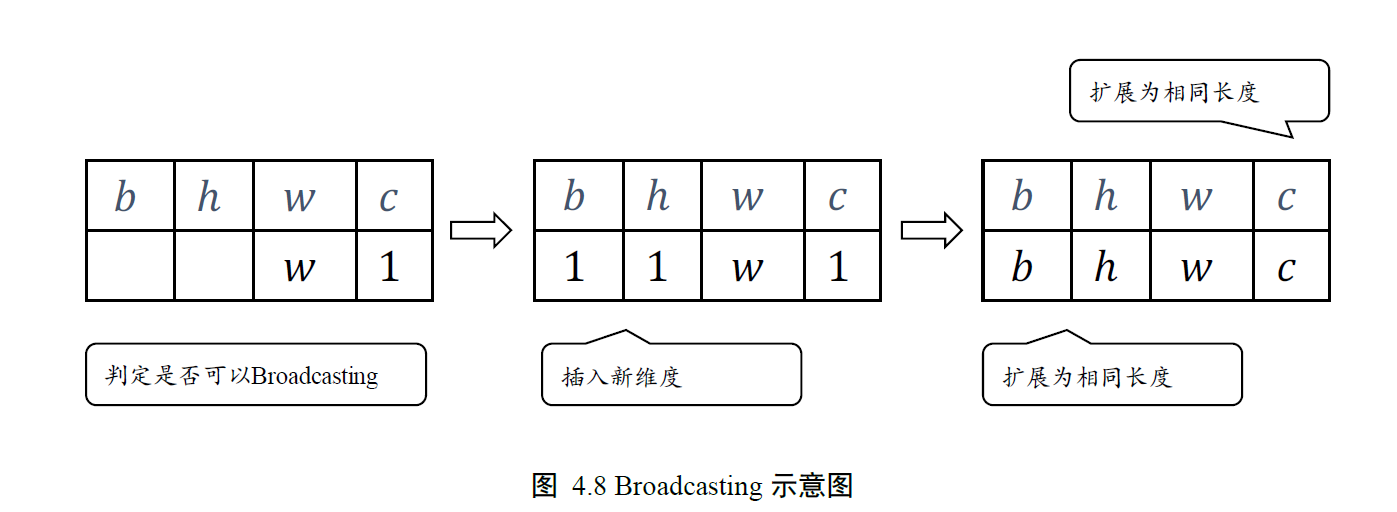
converter实现
converter将tf,caffe模型转换为mnn模型,不涉及计算,未发现广播相关代码
interpreter实现
framework通过SizeComputer::computeOutputSize调用算子op的onComputeSize()函数更新shape信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
bool SizeComputer::computeOutputSize(const MNN::Op* op, const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs) {
auto computeFactory = SizeComputerSuite::get();
// When op is nullptr, it means a copy op
if (nullptr != op) {
auto computer = computeFactory->search(op->type());
if (nullptr != computer) {
bool ret = computer->onComputeSize(op, inputs, outputs);
return ret;
}
}
// Default Set to the same
if (inputs.size() >= 1 && outputs.size() == 1) {
if (inputs[0] == outputs[0]) {
return true;
}
const auto& ib = inputs[0]->buffer();
auto& ob = outputs[0]->buffer();
memcpy(ob.dim, ib.dim, sizeof(halide_dimension_t) * ib.dimensions);
ob.dimensions = ib.dimensions;
ob.type = ib.type;
TensorUtils::getDescribe(outputs[0])->dimensionFormat = TensorUtils::getDescribe(inputs[0])->dimensionFormat;
return true;
}
// Not Support
MNN_PRINT("Can't compute size for %d, name=%s\n", op->type(), op->name()->c_str());
return false;
}
|
以BinaryOpComputer为例,它支持2个输入tensor的加,减,极大,极小之类的运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
Binary
Inputs:
• input0: float32|int32
• input1: float32|int32
Outputs:
• output: float32|int32
Tensorflow op:
• Mul
• Sub
• Add
• Maximum
• RealDiv
• Minimum
• Greater
• BiasAdd
|
CPU backend
查看BinaryOpComputer::onComputeSize()函数,里面有对输入tensor的shape检查,如果2者维度不一样,将尽可能的做broadcast
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
class BinaryOpComputer : public SizeComputer {
public:
static bool outputBool(int operation) {
if (operation == BinaryOpOperation_GREATER_EQUAL) {
return true;
}
if (operation == BinaryOpOperation_GREATER) {
return true;
}
if (operation == BinaryOpOperation_LESS) {
return true;
}
if (operation == BinaryOpOperation_LESS_EQUAL) {
return true;
}
if (operation == BinaryOpOperation_EQUAL) {
return true;
}
return false;
}
virtual bool onComputeSize(const Op* op, const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs) const override {
MNN_ASSERT(2 == inputs.size());
MNN_ASSERT(1 == outputs.size());
// set output type & format
auto input0 = inputs[0], input1 = inputs[1], output = outputs[0];
auto &buffer = output->buffer();
const auto opType = op->main_as_BinaryOp()->opType();
if (outputBool(opType)) {
buffer.type = halide_type_of<int32_t>();
} else {
buffer.type = input0->getType();
}
TensorUtils::getDescribe(output)->dimensionFormat = TensorUtils::getDescribe(input0)->dimensionFormat;
if (input0->dimensions() < input1->dimensions()) {
auto temp = input0;
input0 = input1;
input1 = temp;
}
// if scalar input -> just copy the other
if (input1->dimensions() == 0) {
TensorUtils::copyShape(input0, output);
return true;
}
// else if inputs shape equals -> just copy any one
bool sameShape = input0->elementSize() == input1->elementSize();
if (sameShape) {
TensorUtils::copyShape(input0, output);
return true;
}
// else if broadcast NOT supported -> failed
const int maxDimensions = input0->dimensions();
const int diffDimension = input0->dimensions() - input1->dimensions();
// else broadcast
for (int i = maxDimensions-1; i >=0 ; --i) {
auto input0Length = input0->length(i);
auto input1Length = 1;
if (i >= diffDimension) {
input1Length = input1->length(i-diffDimension);
}
if (input0Length != input1Length && input1Length != 1 && input0Length != 1) {
MNN_PRINT("%d, %d\n", input1Length, input0Length);
return false;
}
buffer.dim[i].extent = std::max(input0Length, input1Length);
}
buffer.dimensions = maxDimensions;
return true;
}
};
REGISTER_SHAPE(BinaryOpComputer, OpType_BinaryOp);
|
onComputeSize()函数首先设置输出变量的类型,再检查两个输入的维度,如果input0比较小的话,交换两个输入以方便后续代码
1
2
3
4
5
|
if (input0->dimensions() < input1->dimensions()) {
auto temp = input0;
input0 = input1;
input1 = temp;
}
|
如果输入变量维度不一致,首先计算维度的最大值和差异值
1
2
|
const int maxDimensions = input0->dimensions();
const int diffDimension = input0->dimensions() - input1->dimensions();
|
接下来一个循环,计算可以broadcast的维度,与之前机制中的算法相同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
for (int i = maxDimensions-1; i >=0 ; --i) {
auto input0Length = input0->length(i);// 输入0的第i位维度
auto input1Length = 1; // 输入1的第i位维度默认为1
// input共有部分维度
if (i >= diffDimension) {
input1Length = input1->length(i-diffDimension); // 取输入1的第i位维度
}
// 二者维度不一致且不是任一个维度为1,这种情况无法做broadcast
if (input0Length != input1Length && input1Length != 1 && input0Length != 1) {
MNN_PRINT("%d, %d\n", input1Length, input0Length);
return false;
}
// 修正两个输入第i位维度值大的那个,完成维度计算
buffer.dim[i].extent = std::max(input0Length, input1Length);
}
|
最后,将输出buffer的维度调整为最大值
1
|
buffer.dimensions = maxDimensions;
|
然后再看具体的计算过程 source/backend/cpu/CPUBinary.cpp
算子onExecute()函数根据传入的计算类型,调用相应模板完成计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
template <typename T>
ErrorCode CPUBinary<T>::onExecute(const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs) {
if (nullptr != mEltWise.get()) {
return mEltWise->onExecute(inputs, outputs);
}
auto input = inputs[0];
auto input1 = inputs[1];
auto output = outputs[0];
switch (mType) {
case BinaryOpOperation_MUL:
_binaryOp<T, T, BinaryMul<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_ADD:
_binaryOp<T, T, BinaryAdd<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_SUB:
_binaryOp<T, T, BinarySub<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_REALDIV:
_binaryOp<T, T, BinaryRealDiv<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_MINIMUM:
_binaryOp<T, T, BinaryMin<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_MAXIMUM:
_binaryOp<T, T, BinaryMax<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_GREATER:
_binaryOp<T, int32_t, BinaryGreater<T, T, int32_t>>(input, input1, output);
break;
case BinaryOpOperation_LESS:
_binaryOp<T, T, BinaryLess<T, T, int32_t>>(input, input1, output);
break;
case BinaryOpOperation_LESS_EQUAL:
_binaryOp<T, T, BinaryLessEqual<T, T, int32_t>>(input, input1, output);
break;
case BinaryOpOperation_GREATER_EQUAL:
_binaryOp<T, T, BinaryGreaterEqual<T, T, int32_t>>(input, input1, output);
break;
case BinaryOpOperation_EQUAL:
_binaryOp<T, T, BinaryEqual<T, T, int32_t>>(input, input1, output);
break;
case BinaryOpOperation_FLOORDIV:
_binaryOp<T, T, BinaryFloorDiv<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_FLOORMOD:
_binaryOp<T, T, BinaryFloorMod<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_POW:
_binaryOp<T, T, BinaryPow<T, T, T>>(input, input1, output);
break;
case BinaryOpOperation_SquaredDifference:
_binaryOp<T, T, BinarySquaredDifference<T, T, T>>(input, input1, output);
break;
default:
MNN_ASSERT(false);
break;
}
return NO_ERROR;
}
|
上述计算的核心是_binaryOp()函数,发现不是相同类型的输入,那么根据之前计算的输出tensor shape参数循环计算结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
template <typename Tin, typename Tout, typename Func>
static ErrorCode _binaryOp(Tensor* input0, Tensor* input1, Tensor* output) {
Func f;
const int input0DataCount = input0->elementSize();
const int input1DataCount = input1->elementSize();
const Tin* input0Data = input0->host<Tin>();
const Tin* input1Data = input1->host<Tin>();
Tout* outputData = output->host<Tout>();
if (input0DataCount == 1) { // data count == 1, not only mean scalar input, maybe of shape (1, 1, 1, ...,1)
for (int i = 0; i < input1DataCount; i++) {
outputData[i] = static_cast<Tout>(f(input0Data[0], input1Data[i]));
}
} else if (input1DataCount == 1) {
for (int i = 0; i < input0DataCount; i++) {
outputData[i] = static_cast<Tout>(f(input0Data[i], input1Data[0]));
}
} else { // both input contains more than one element,which means no scalar input
bool sameShape = input0->elementSize() == input1->elementSize();
if (sameShape) { // two inputs have the same shape, apply element-wise operation
for (int i = 0; i < input0DataCount; i++) {
outputData[i] = static_cast<Tout>(f(input0Data[i], input1Data[i]));
}
} else { // not the same shape, use broadcast
#define MAX_DIM 6
// 输入shape类型不一样,根据之前计算的output->dimensions完成broadcast计算
MNN_ASSERT(output->dimensions() <= MAX_DIM);
int dims[MAX_DIM];
int stride[MAX_DIM];
int iStride0[MAX_DIM];
int iStride1[MAX_DIM];
// 更新输入,输出tensor最多6维对应的dim,strde信息
for (int i = MAX_DIM - 1; i >= 0; --i) {
// dim, stride默认值
dims[i] = 1;
stride[i] = 0;
iStride0[i] = 0;
iStride1[i] = 0;
// 输入索引
int input0I = i - (output->dimensions() - input0->dimensions());
int input1I = i - (output->dimensions() - input1->dimensions());
if (i < output->dimensions()) {
// 已有数据,填实际的dim,stride
dims[i] = output->length(i);
stride[i] = output->stride(i);
}
if (input0I >= 0 && input0->length(input0I) != 1) {
// 原有数据维度,填实际stride,否则stride用默认值0,重复使用现有数据
iStride0[i] = input0->stride(input0I);
}
if (input1I >= 0 && input1->length(input1I) != 1) {
// 原有数据维度,填实际stride,否则stride用默认值0,重复使用现有数据
iStride1[i] = input1->stride(input1I);
}
}
// 根据“索引地址=首地址 + x * stride[i]循环计算6维结果”
for (int w = 0; w < dims[5]; ++w) {
auto ow = outputData + w * stride[5];
auto i0w = input0Data + w * iStride0[5];
auto i1w = input1Data + w * iStride1[5];
#define PTR(x, y, i) \
auto o##x = o##y + x * stride[i]; \
auto i0##x = i0##y + x * iStride0[i]; \
auto i1##x = i1##y + x * iStride1[i]
for (int v = 0; v < dims[4]; ++v) {
PTR(v, w, 4);
for (int u = 0; u < dims[3]; ++u) {
PTR(u, v, 3);
for (int z = 0; z < dims[2]; ++z) {
PTR(z, u, 2);
for (int y = 0; y < dims[1]; ++y) {
PTR(y, z, 1);
for (int x = 0; x < dims[0]; ++x) {
PTR(x, y, 0);
// 此处对应一个原子操作
*ox = static_cast<Tout>(f(*i0x, *i1x));
}
}
}
}
}
}
#undef MAX_DIM
#undef PTR
}
// broadcast-capable check is done in compute size
}
return NO_ERROR;
}
|
此处最多循环6维,最外面几层循环次数为1。为什么最大为6??岂不是大于6维的输入会没法计算?
之前拿到的mnn版本为0.2.1.4, 需要check最新的0.2.1.6版本,可能增加了一些支持broadcast的算子
看source/backend/metal/MetalBinary.mm里面的MetalBinary::onExecute()函数,如果shape不一致,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
ErrorCode MetalBinary::onExecute(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) {
auto backend = static_cast<MetalBackend *>(this->backend());
auto context = (__bridge MNNMetalContext *)backend->context();
auto input0 = inputs[0], input1 = inputs[1], output = outputs[0];
const int input0_data_count = (int)input0->elementSize();
const int input1_data_count = (int)input1->elementSize();
// scalar support
int iw0 = input0->width(), ih0 = input0->height();
int iw1 = input1->width(), ih1 = input1->height();
int ow = output->width(), oh = output->height(), oc = output->channel(), ob = output->batch();
iw0 = iw0 == 0 ? 1 : iw0;
ih0 = ih0 == 0 ? 1 : ih0;
iw1 = iw1 == 0 ? 1 : iw1;
ih1 = ih1 == 0 ? 1 : ih1;
ow = ow == 0 ? 1 : ow;
oh = oh == 0 ? 1 : oh;
oc = oc == 0 ? 1 : oc;
ob = ob == 0 ? 1 : ob;
bool same_shape = true;
// scalar input
if (inputs[0]->buffer().dimensions == 0 || inputs[1]->buffer().dimensions == 0) {
// do nothing
}
// same shape
else if (inputs[0]->buffer().dimensions == inputs[1]->buffer().dimensions) {
for (int i = 0; i < inputs[0]->buffer().dimensions; i++) {
if (inputs[0]->buffer().dim[i].extent != inputs[1]->buffer().dim[i].extent) {
same_shape = false;
break;
}
}
}
// different shape
else {
same_shape = false;
}
// encode
auto output_dimensions = output->buffer().dimensions;
auto shape = [context newDeviceBuffer:6 * sizeof(int) access:CPUWriteOnly];
auto encoder = [context encoder];
if (same_shape == false) {
// 维度不一致情况,需要计算各个维度的dim,stride,然后才能计算
// dim
auto dimsIn0Buffer = [context newDeviceBuffer:sizeof(int) * output_dimensions access:CPUWriteOnly];
auto dimsIn1Buffer = [context newDeviceBuffer:sizeof(int) * output_dimensions access:CPUWriteOnly];
int *dims0 = (int *)dimsIn0Buffer.contents;
int *dims1 = (int *)dimsIn1Buffer.contents;
for (int i = 0; i < output_dimensions; i++) {
dims0[i] = dims1[i] = 1;
}
for (int i = input0->buffer().dimensions - 1, j = output_dimensions - 1; i >= 0; i--, j--) {
dims0[j] = input0->buffer().dim[i].extent;
}
for (int i = input1->buffer().dimensions - 1, j = output_dimensions - 1; i >= 0; i--, j--) {
dims1[j] = input1->buffer().dim[i].extent;
}
// strides & shape
auto stridesIn0Buffer = [context newDeviceBuffer:sizeof(int) * output_dimensions access:CPUWriteOnly];
auto stridesIn1Buffer = [context newDeviceBuffer:sizeof(int) * output_dimensions access:CPUWriteOnly];
auto stridesOutBuffer = [context newDeviceBuffer:sizeof(int) * output_dimensions access:CPUWriteOnly];
int *input0_strides = (int *)stridesIn0Buffer.contents;
int *input1_strides = (int *)stridesIn1Buffer.contents;
int *output_strides = (int *)stridesOutBuffer.contents;
int input_data_count0 = 1, input_data_count1 = 1;
int output_data_count = 1;
// 更新各个维度的stride信息
for (int i = output_dimensions - 1; i >= 0; i--) {
input0_strides[i] = input_data_count0;
input_data_count0 *= dims0[i];
input1_strides[i] = input_data_count1;
input_data_count1 *= dims1[i];
output_strides[i] = output_data_count;
output_data_count *= output->buffer().dim[i].extent;
}
((int *)shape.contents)[0] = input0_data_count;
((int *)shape.contents)[1] = input1_data_count;
((int *)shape.contents)[2] = output_data_count;
((int *)shape.contents)[3] = ow;
((int *)shape.contents)[4] = ow * oh;
((int *)shape.contents)[5] = output_dimensions;
// encode
auto bandwidth = [context load:@"binary_notshape" encoder:encoder];
[encoder setBuffer:(__bridge id<MTLBuffer>)(void *)input0->deviceId() offset:0 atIndex:0];
[encoder setBuffer:(__bridge id<MTLBuffer>)(void *)input1->deviceId() offset:0 atIndex:1];
[encoder setBuffer:(__bridge id<MTLBuffer>)(void *)output->deviceId() offset:0 atIndex:2];
[encoder setBuffer:shape offset:0 atIndex:3];
[encoder setBuffer:mBinaryType offset:0 atIndex:4];
[encoder setBuffer:dimsIn0Buffer offset:0 atIndex:5];
[encoder setBuffer:dimsIn1Buffer offset:0 atIndex:6];
[encoder setBuffer:stridesIn0Buffer offset:0 atIndex:7];
[encoder setBuffer:stridesIn1Buffer offset:0 atIndex:8];
[encoder setBuffer:stridesOutBuffer offset:0 atIndex:9];
[context dispatchEncoder:encoder threads:{ (NSUInteger) output_data_count, 1, 1 } bandwidth:bandwidth];
} else {
int outdatacount = 0;
if (input0_data_count == input1_data_count) {
outdatacount = input0_data_count;
} else {
outdatacount = input0_data_count > input1_data_count ? input0_data_count : input1_data_count;
}
((int *)shape.contents)[0] = input0_data_count;
((int *)shape.contents)[1] = input1_data_count;
((int *)shape.contents)[2] = outdatacount;
((int *)shape.contents)[3] = ow;
((int *)shape.contents)[4] = ow * oh;
((int *)shape.contents)[5] = output_dimensions;
auto bandwidth = [context load:@"binary_normal" encoder:encoder];
[encoder setBuffer:(__bridge id<MTLBuffer>)(void *)input0->deviceId() offset:0 atIndex:0];
[encoder setBuffer:(__bridge id<MTLBuffer>)(void *)input1->deviceId() offset:0 atIndex:1];
[encoder setBuffer:(__bridge id<MTLBuffer>)(void *)output->deviceId() offset:0 atIndex:2];
[encoder setBuffer:shape offset:0 atIndex:3];
[encoder setBuffer:mBinaryType offset:0 atIndex:4];
[context dispatchEncoder:encoder threads:{ (NSUInteger) outdatacount, 1, 1 } bandwidth:bandwidth];
}
[encoder endEncoding];
MNN_PRINT_ENCODER(context, encoder);
return NO_ERROR;
}
|
vulkan backend
vulkan后端不支持broadcast,只是为NHWC和NC4HW4 做了优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
ErrorCode VulkanBinary::onEncode(const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs,
const VulkanCommandPool::Buffer* cmdBuffer) {
MNN_ASSERT(2 == inputs.size());
MNN_ASSERT(1 == outputs.size());
auto input0 = inputs[0];
auto input1 = inputs[1];
auto output = outputs[0];
MNN_ASSERT(input0->getType().code == halide_type_float);
const auto intputFormat = TensorUtils::getDescribe(input0)->dimensionFormat;
if (intputFormat == MNN_DATA_FORMAT_NHWC) {
// for NHWC input
std::vector<VkDescriptorType> types{VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER,
VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER};
switch (mType) {
case BinaryOpOperation_MUL:
mBinaryPipeline = mVkBackend->getPipeline("glsl_elementwiseMulBuffer_comp", types);
break;
case BinaryOpOperation_ADD:
mBinaryPipeline = mVkBackend->getPipeline("glsl_elementwiseAddBuffer_comp", types);
break;
case BinaryOpOperation_SUB:
mBinaryPipeline = mVkBackend->getPipeline("glsl_elementwiseSubBuffer_comp", types);
break;
default:
MNN_PRINT("Not Supported Binary Operation: %d\n", mType);
MNN_ASSERT(false);
break;
}
const int input0Elements = input0->elementSize();
const int input1Elements = input1->elementSize();
const int outputElements = output->elementSize();
auto binaryOpParam = reinterpret_cast<ConstBuffer*>(mConstBuffer->map());
::memset(binaryOpParam, 0, sizeof(ConstBuffer));
if (input0Elements == 1) {
binaryOpParam->stride[0] = 0;
binaryOpParam->stride[1] = 1;
binaryOpParam->stride[2] = 1;
binaryOpParam->stride[3] = outputElements;
} else if (input1Elements == 1) {
binaryOpParam->stride[0] = 1;
binaryOpParam->stride[1] = 0;
binaryOpParam->stride[2] = 1;
binaryOpParam->stride[3] = outputElements;
} else if (input0Elements == input1Elements) {
binaryOpParam->stride[0] = 1;
binaryOpParam->stride[1] = 1;
binaryOpParam->stride[2] = 1;
binaryOpParam->stride[3] = outputElements;
} else {
return NOT_SUPPORT;
}
mConstBuffer->flush(true, 0, sizeof(ConstBuffer));
mConstBuffer->unmap();
mDescriptorSet.reset(mBinaryPipeline->createSet());
mDescriptorSet->writeBuffer(reinterpret_cast<VkBuffer>(output->deviceId()), 0, output->size());
mDescriptorSet->writeBuffer(reinterpret_cast<VkBuffer>(input0->deviceId()), 1, input0->size());
mDescriptorSet->writeBuffer(reinterpret_cast<VkBuffer>(input1->deviceId()), 2, input1->size());
mDescriptorSet->writeBuffer(mConstBuffer->buffer(), 3, mConstBuffer->size());
mBinaryPipeline->bind(cmdBuffer->get(), mDescriptorSet->get());
cmdBuffer->barrierSource(reinterpret_cast<VkBuffer>(input0->deviceId()), 0, input0->size());
cmdBuffer->barrierSource(reinterpret_cast<VkBuffer>(input1->deviceId()), 0, input1->size());
vkCmdDispatch(cmdBuffer->get(), UP_DIV(output->elementSize(), 8), 1, 1);
} else {
// for NC4HW4 input
std::vector<VkDescriptorType> types{VK_DESCRIPTOR_TYPE_STORAGE_IMAGE, VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER};
switch (mType) {
case BinaryOpOperation_ADD:
mBinaryPipeline = mVkBackend->getPipeline("glsl_elementwiseAdd_comp", types);
break;
case BinaryOpOperation_MUL:
mBinaryPipeline = mVkBackend->getPipeline("glsl_elementwiseMul_comp", types);
break;
default:
MNN_PRINT("Not Supported Binary Operation: %d\n", mType);
MNN_ASSERT(false);
break;
}
const int iw = input0->width();
const int ih = input0->height();
MNN_ASSERT(input0->dimensions() == input1->dimensions());
const int icDiv4 = UP_DIV(input0->channel(), 4);
auto binaryOpParam = reinterpret_cast<ConstBuffer*>(mConstBuffer->map());
::memset(binaryOpParam, 0, sizeof(ConstBuffer));
binaryOpParam->imgSize[0] = iw;
binaryOpParam->imgSize[1] = ih;
binaryOpParam->imgSize[2] = icDiv4 * input0->batch();
binaryOpParam->imgSize[3] = 0;
mConstBuffer->flush(true, 0, sizeof(ConstBuffer));
mConstBuffer->unmap();
auto sampler = mVkBackend->getCommonSampler();
mDescriptorSet.reset(mBinaryPipeline->createSet());
mDescriptorSet->writeImage(reinterpret_cast<VkImageView>(output->deviceId()), sampler->get(),
VK_IMAGE_LAYOUT_GENERAL, 0);
mDescriptorSet->writeImage(reinterpret_cast<VkImageView>(input0->deviceId()), sampler->get(),
VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL, 1);
mDescriptorSet->writeImage(reinterpret_cast<VkImageView>(input1->deviceId()), sampler->get(),
VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL, 2);
mDescriptorSet->writeBuffer(mConstBuffer->buffer(), 3, mConstBuffer->size());
mBinaryPipeline->bind(cmdBuffer->get(), mDescriptorSet->get());
vkCmdDispatch(cmdBuffer->get(), UP_DIV(iw, 8), UP_DIV(ih, 8), UP_DIV(icDiv4 * input0->batch(), 4));
}
return NO_ERROR;
}
|
opencl backend
用EltwiseExecution实现的binaryop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
class EltwiseCreator : public OpenCLBackend::Creator {
public:
virtual Execution *onCreate(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs,
const MNN::Op *op, Backend *backend) const override {
if (op->type() == OpType_Eltwise) {
switch (op->main_as_Eltwise()->type()) {
case EltwiseType_SUM:
return new EltwiseExecution(inputs, "in0+in1", backend);
case EltwiseType_PROD:
return new EltwiseExecution(inputs, "in0*in1", backend);
case EltwiseType_MAXIMUM:
return new EltwiseExecution(inputs, "fmax(in0, in1)", backend);
default:
break;
}
return nullptr;
}
if (op->type() == OpType_BinaryOp) {
MNN_ASSERT(inputs.size() > 1);
switch (op->main_as_BinaryOp()->opType()) {
case BinaryOpOperation_ADD:
return new EltwiseExecution(inputs, "in0+in1", backend);
case BinaryOpOperation_SUB:
return new EltwiseExecution(inputs, "in0-in1", backend);
case BinaryOpOperation_MUL:
return new EltwiseExecution(inputs, "in0*in1", backend);
case BinaryOpOperation_POW:
return new EltwiseExecution(inputs, "pow(in0, in1)", backend);
case BinaryOpOperation_DIV:
return new EltwiseExecution(inputs, "in0/in1", backend);
case BinaryOpOperation_MAXIMUM:
return new EltwiseExecution(inputs, "fmax(in0,in1)", backend);
case BinaryOpOperation_MINIMUM:
return new EltwiseExecution(inputs, "fmin(in0,in1)", backend);
case BinaryOpOperation_REALDIV:
return new EltwiseExecution(inputs, "in0/in1", backend);
default:
break;
}
return nullptr;
}
return nullptr;
}
};
|
EltwiseExecution初始化的时候传进来mBroadcast参数
1
2
3
4
5
6
|
EltwiseExecution::EltwiseExecution(const std::vector<Tensor *> &inputs, const std::string &compute, Backend *backend, float operatorData, bool broadCast)
: CommonExecution(backend) {
mBroadCast = broadCast;
mOperatorData = operatorData;
mBuildOptions.emplace("-DOPERATOR=" + compute);
}
|
EltwiseExecution::onResize()函数根据数据存贮类型加载不同的opencl shader完成计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
if (mBroadCast) {
if (nhwc_0[3] != nhwc_1[3]) {
if (nhwc_0[3] == 1) {
unit.kernel = (wh_0[0] != 1 && wh_0[1] != 1) ?
runTime->buildKernel("binary",
"binary_1toM_channel_broadcast_on_awh", mBuildOptions) :
runTime->buildKernel("binary",
"binary_1toM_channel_broadcast_on_1wh", mBuildOptions);
unit.kernel.setArg(0, openCLImage(input0));
unit.kernel.setArg(1, openCLImage(input));
unit.kernel.setArg(4, wh_0);
unit.kernel.setArg(5, wh1);
} else {
unit.kernel = (wh1[0] != 1 && wh1[1] != 1) ?
runTime->buildKernel("binary",
"binary_1toM_channel_broadcast_on_awh", mBuildOptions) :
runTime->buildKernel("binary",
"binary_1toM_channel_broadcast_on_1wh", mBuildOptions);
unit.kernel.setArg(0, openCLImage(input));
unit.kernel.setArg(1, openCLImage(input0));
unit.kernel.setArg(4, wh1);
unit.kernel.setArg(5, wh_0);
}
unit.kernel.setArg(2, openCLImage(outputs[0]));
unit.kernel.setArg(3, nhwcArray);
unit.kernel.setArg(6, wh);
} else {
unit.kernel = runTime->buildKernel("binary",
"binary_same_channel_broadcast", mBuildOptions);
if (wh_0[0] == 1 || wh_0[1] == 1) {
unit.kernel.setArg(0, openCLImage(input0));
unit.kernel.setArg(1, openCLImage(input));
unit.kernel.setArg(4, wh_0);
unit.kernel.setArg(5, wh1);
} else {
unit.kernel.setArg(0, openCLImage(input));
unit.kernel.setArg(1, openCLImage(input0));
unit.kernel.setArg(4, wh1);
unit.kernel.setArg(5, wh_0);
}
unit.kernel.setArg(2, openCLImage(outputs[0]));
unit.kernel.setArg(3, nhwcArray);
unit.kernel.setArg(6, wh);
}
} else {
unit.kernel = runTime->buildKernel("binary", "binary", mBuildOptions);
unit.kernel.setArg(0, openCLImage(input0));
unit.kernel.setArg(1, openCLImage(input));
unit.kernel.setArg(2, openCLImage(outputs[0]));
unit.kernel.setArg(3, nhwcArray);
unit.kernel.setArg(4, wh);
unit.kernel.setArg(5, input1Stride);
}
|
opencl shader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
__kernel void binary_same_channel_broadcast(__read_only image2d_t input0, __read_only image2d_t input1, __write_only image2d_t output,
int4 shape, int2 whInput0, int2 whInput1, int2 whOutput) {
int2 pos = (int2)(get_global_id(0), get_global_id(1));
int4 nhwc = (int4)(pos.y/shape.y, pos.y%shape.y, pos.x%shape.z, pos.x/shape.z);
if (nhwc.x >= shape.x && nhwc.w >= shape.w)
return;
FLOAT4 in0, in1;
int2 pos0, pos1;
if (whInput0.x == 1) { // Tensor 0 width length 1
pos0 = (int2)(nhwc.w*whInput0.x, nhwc.x*whOutput.y+nhwc.y);
in0 = RI_F(input0, SAMPLER, pos0);
pos1 = (whInput1.y != 1) ?
(int2)(nhwc.w*whOutput.x+nhwc.z, nhwc.x*whOutput.y+nhwc.y) :
(int2)(nhwc.w*whOutput.x+nhwc.z, 0);
} else if (whInput0.y == 1) { // Tensor 0 height length 1
pos0 = (int2)(nhwc.w*whOutput.x+nhwc.z, 0);
in0 = RI_F(input0, SAMPLER, pos0);
pos1 = (whInput1.x != 1) ?
(int2)(nhwc.w*whOutput.x+nhwc.z, nhwc.x*whOutput.y+nhwc.y) :
(int2)(nhwc.w*whInput1.x, nhwc.x*whOutput.y+nhwc.y);
} else if (whInput0.x == 1 && whInput0.y == 1) {
pos0 = (int2)(nhwc.w*whInput0.x, 0);
in0 = RI_F(input0, SAMPLER, pos0);
pos1 = (int2)(nhwc.w*whOutput.x+nhwc.z, nhwc.x*whOutput.y+nhwc.y);
}
in1 = RI_F(input1, SAMPLER, pos1);
WI_F(output, pos, OPERATOR);
}
|
