高通AI体系分析

文章目录
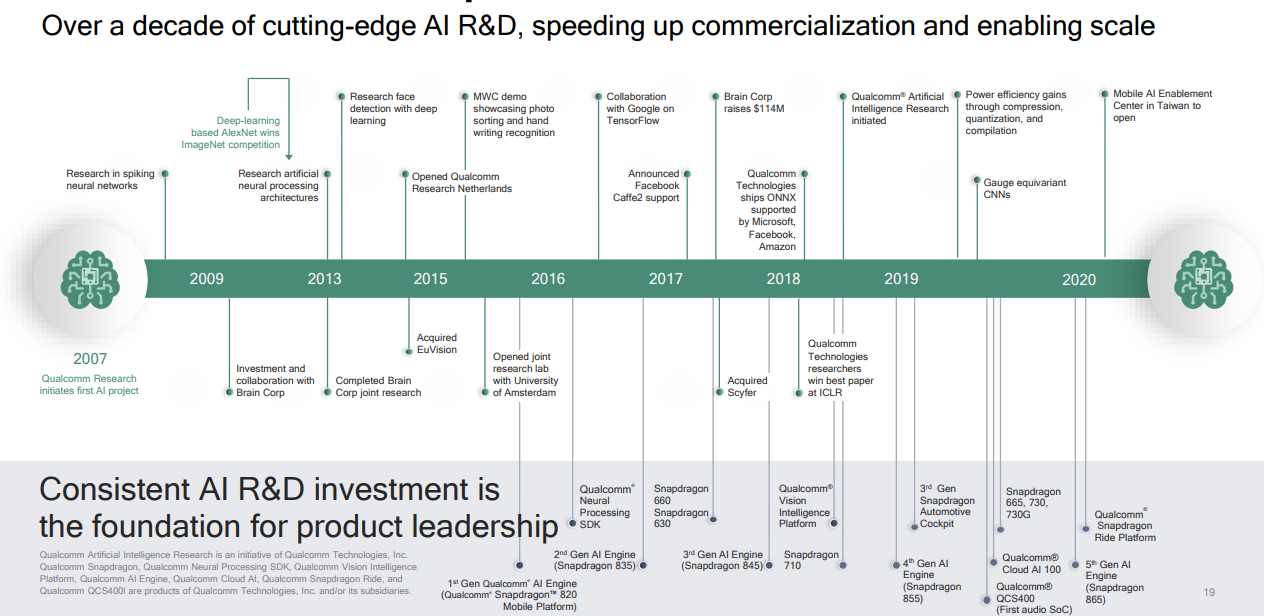
高通AI发展历史
https://www.qualcomm.com/media/documents/files/making-ai-ubiquitous.pdf
硬件
- 各种手机芯片:660,710,855,865
- qualcomm cloud AI 100:2019年发布,7nm专用人工智能处理器,350 tops性能,云端推理平台
- QCS 40X:2019年发布,audio chip
软件:
- 主流AI框架的支持,包括TF,caffe,pytorch,onnx,paddlepaddle等
- 硬件加速库:fastcv,Adreno GPU SDK,Hexagon DSP SDK,Machine Vision SDK
高通AI框架及生态
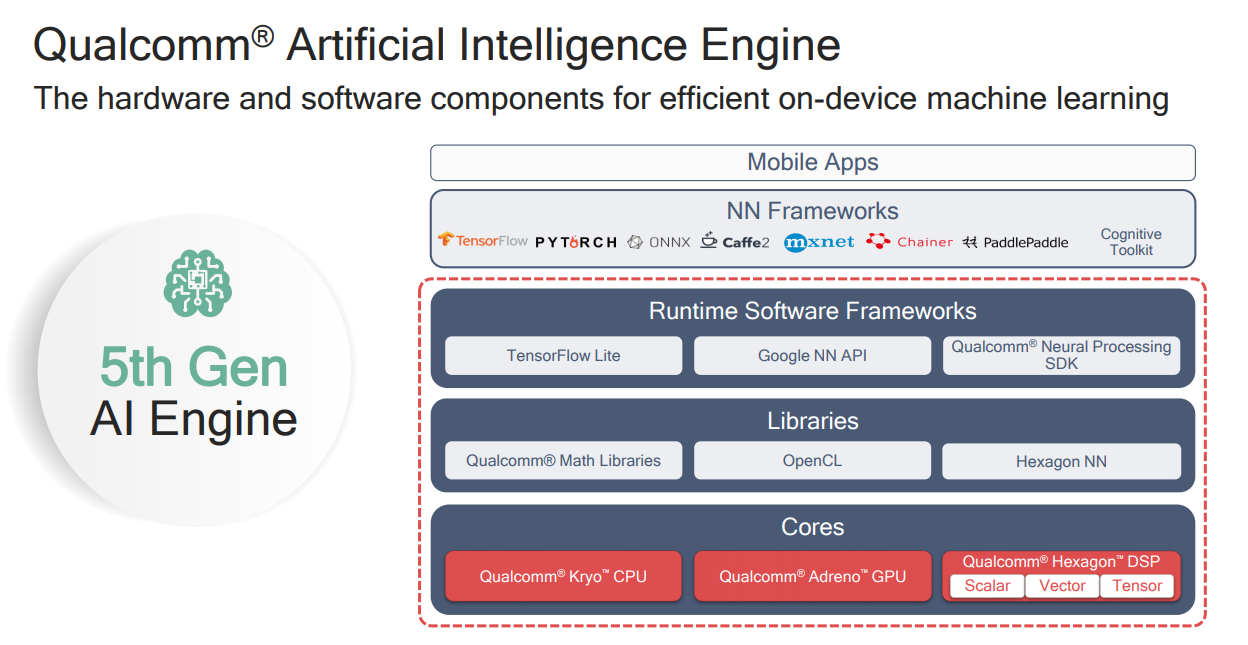
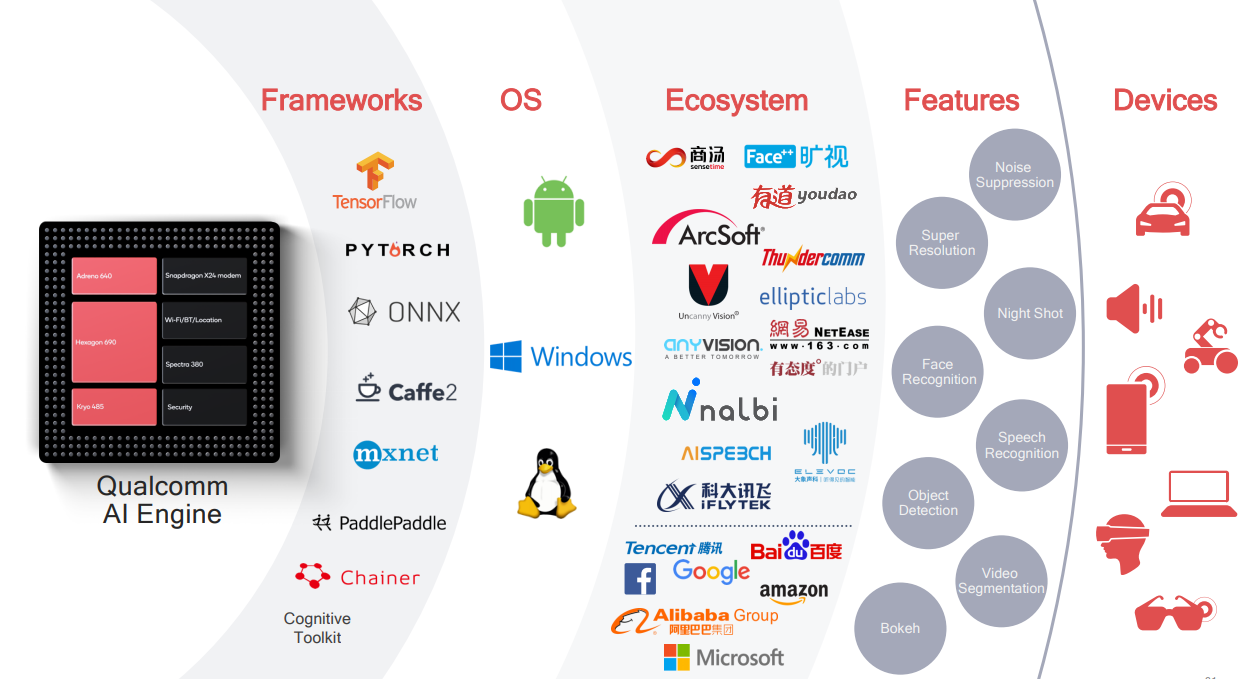
865特性框图
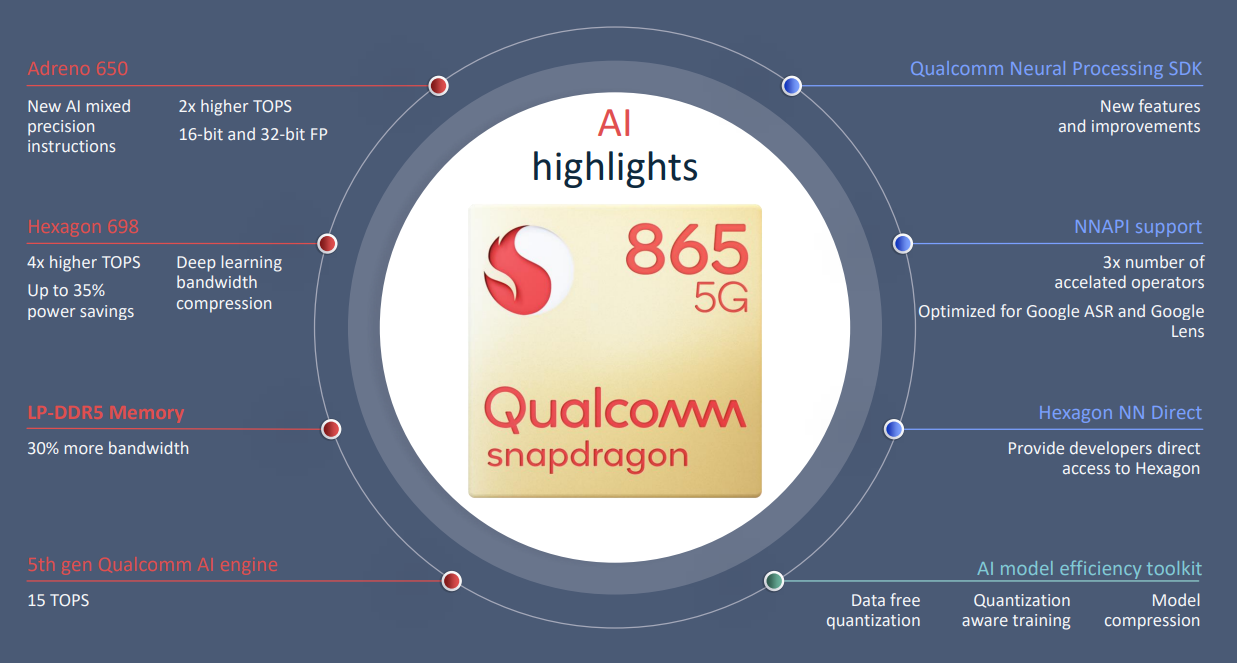
高通AI软件生态
高通的AI生态主要分4个部分,如下述列表所示
-
Neural Network Optimization:Qualcomm Neural Processing SDK for AI,https://www.youtube.com/watch?v=CK-zwbMfDxk&feature=youtu.be 类似MNN的AI推理框架,将tf,caffe模型转换成dlc格式私有模型,在AI runtime上运行推理
- Android and Linux runtimes for neural network model execution
- Acceleration support for Qualcomm® Hexagon™ DSPs, Qualcomm® Adreno™ GPUs and Qualcomm® Kryo™, CPUs1
- Support for models in Caffe, Caffe2, ONNX, and TensorFlow formats2
- APIs for controlling loading, execution and scheduling on the runtimes
- Desktop tools for model conversion
- Performance benchmark for bottleneck identification
- Sample code and tutorials
- HTML Documentation
-
App Performance Optimization:Snapdragon Developer Tools 应用调试,电源,性能优化工具等
-
Specialized Core Optimization GPU,DSP相关加速库
- Adreno GPU SDK opengl es,opencl,vulken开发库
- Hexagon DSP SDK
-
smart camera解决方案 面向传统机器视觉领域,machine version用于嵌入式开发板,fastcv用于移动平台
- Machine Vision SDK:engineered to supply cutting-edge computer vision algorithms for localization, feature recognition, and obstacle detection on Qualcomm processors.
- FastCV SDK :offers a mobile-optimized computer vision (CV) library that includes the most frequently used vision processing functions and helping you to add new user experiences into your camera-based apps like gesture recognition, face detection, tracking, text recognition, and augmented reality (AR)
Snapdragon Neural Processing Engine
发布形式
c++,java接口,so形式
|
|
能力
- Execute an arbitrarily deep neural network
- Execute the network on the SnapdragonTM CPU, the AdrenoTM GPU or the HexagonTM DSP.
- Debug the network execution on x86 Ubuntu Linux
- Convert Caffe, Caffe2, ONNXTM and TensorFlowTM models to a SNPE Deep Learning Container (DLC) file
- Quantize DLC files to 8 bit fixed point for running on the Hexagon DSP
- Debug and analyze the performance of the network with SNPE tools
- Integrate a network into applications and other code via C++ or Java
流程图
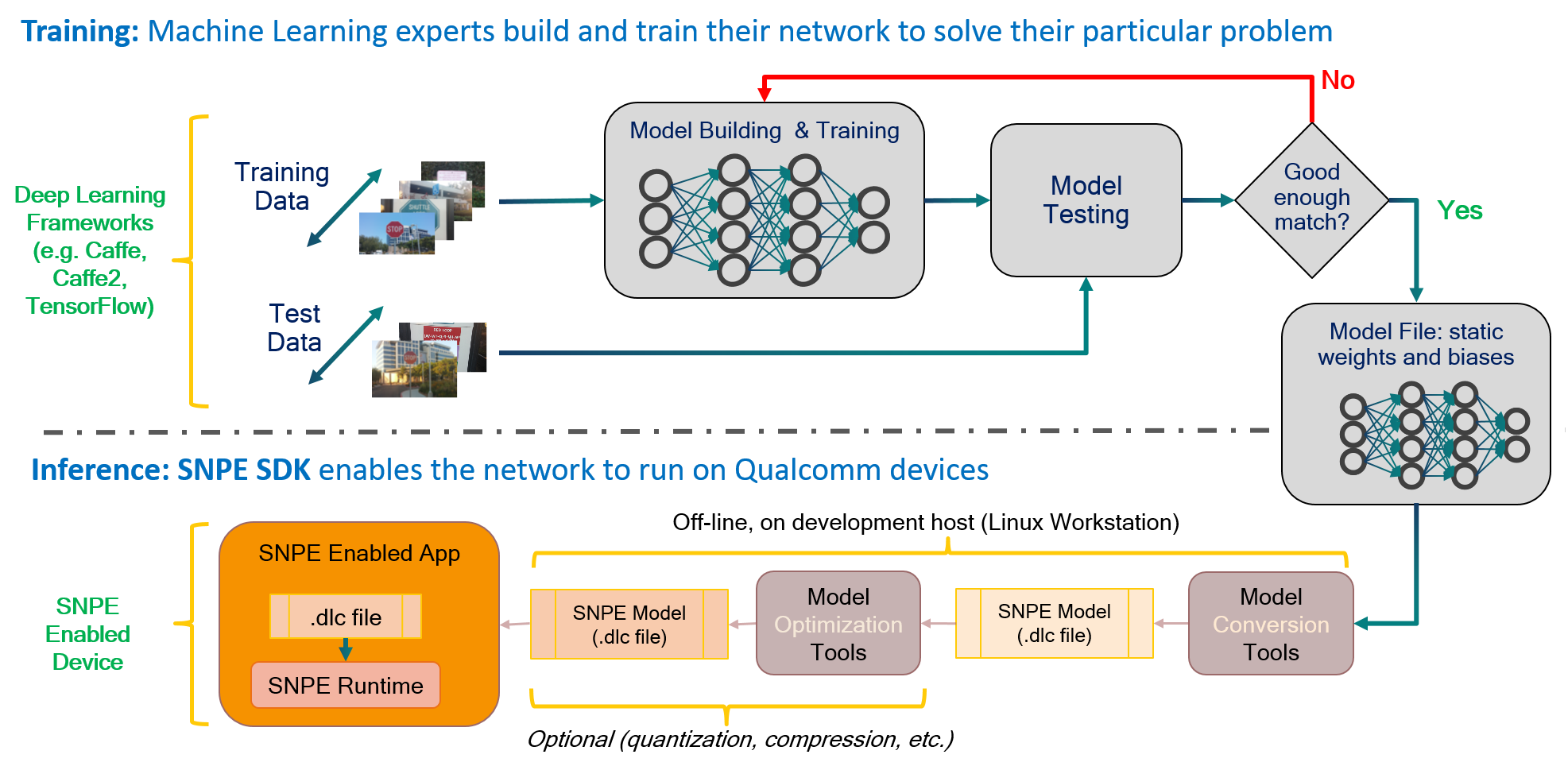
The basic SNPE workflow consists of only a few steps:
- Convert the network model to a DLC file that can be loaded by SNPE.
- Optionally quantize the DLC file for running on the Hexagon DSP.
- Prepare input data for the model.
- Load and execute the model using SNPE runtime.
目录结构
| SDK Asset | Type | Compiler | C++ STL | Description |
|---|---|---|---|---|
| android | lib | - | - | Android aar file used to include SNPE into your application |
| bin/x86_64-linux-clang | binary | clang3.4 | gnustl | x86 Linux binaries |
| bin/arm-android-clang6.0 | binary | clang6.0 | libc++ | ARM Android binaries |
| bin/aarch64-android-clang6.0 | binary | clang6.0 | libc++ | Aarch64 Android binaries |
| bin/arm-linux-gcc4.9sf | binary | gcc4.9 | gnustl | Arm Linux Soft Float binaries |
| bin/aarch64-linux-gcc4.9 | binary | gcc4.9 | gnustl | Aarch64 Linux binaries |
| bin/arm-oe-linux-gcc6.4hf | binary | gcc6.4 | gnustl | Arm Linux Hard Float binaries |
| bin/aarch64-oe-linux-gcc6.4 | binary | gcc6.4 | gnustl | Aarch64 Linux binaries |
| lib/x86_64-linux-clang | lib | clang3.4 | gnustl | x86 Linux libraries |
| lib/arm-android-clang6.0 | lib | clang6.0 | libc++ | ARM Android libraries |
| lib/aarch64-android-clang6.0 | lib | clang6.0 | libc++ | Aarch64 Android libraries |
| lib/dsp | lib | - | - | Hexagon DSP runtime libraries |
| lib/arm-linux-gcc4.9sf | lib | gcc4.9 | gnustl | ARM Linux Soft Float libraries |
| lib/aarch64-linux-gcc4.9 | lib | gcc4.9 | gnustl | Aarch64 Linux libraries |
| lib/arm-oe-linux-gcc6.4hf | lib | gcc6.4 | gnustl | ARM Linux Hard Float libraries |
| lib/aarch64-oe-linux-gcc6.4 | lib | gcc6.4 | gnustl | Aarch64 Linux libraries |
| lib/python | lib | - | - | SNPE python model tools modules |
| include/zdl/SNPE | include dir | - | - | SNPE SDK API header files |
| examples | examples dir | - | - | Source code sample applications in Native C++ and Android Java |
| doc | documents | - | - | User and reference API guide |
| benchmarks | scripts | - | - | Benchmark framework to gather runtime performance data on devices |
| models | resources | - | - | Example neural network models |
重点文件
| File | Type | Details | Location |
|---|---|---|---|
| envsetup.sh | script | Script to setup various environment variables needed to run SDK tools and binaries | $SNPE_ROOT/bin |
| snpe-caffe-to-dlc | script | Script to convert a Caffe model to a DLC file | $SNPE_ROOT/bin/x86_64-linux-clang |
| snpe-caffe2-to-dlc | script | Script to convert a Caffe2 model to a DLC file | $SNPE_ROOT/bin/x86_64-linux-clang |
| snpe-onnx-to-dlc | script | Script to convert a ONNX model to a DLC file | $SNPE_ROOT/bin/x86_64-linux-clang |
| snpe-tensorflow-to-dlc | script | Script to convert a TensorFlow model to a DLC file | $SNPE_ROOT/bin/x86_64-linux-clang |
| snpe-dlc-quantize | executable | Used to quantize a DLC file using 8 bit quantization | $SNPE_ROOT/bin/x86_64-linux-clang |
| snpe-diagview | executable | View SNPE timing output | $SNPE_ROOT/bin/x86_64-linux-clang |
| snpe-dlc-info | script | Script to print various DLC file information | $SNPE_ROOT/bin/x86_64-linux-clang |
| snpe_bench.py | script | Script to run DLC model on device and collect benchmark information | $SNPE_ROOT/benchmarks |
| snpe-net-run | executable | Example binary that can run a neural network | $SNPE_ROOT/bin/x86_64-linux-clang $SNPE_ROOT/bin/arm-android-clang6.0 $SNPE_ROOT/bin/aarch64-android-clang6.0 $SNPE_ROOT/bin/arm-linux-gcc4.9sf $SNPE_ROOT/bin/aarch64-linux-gcc4.9 $SNPE_ROOT/bin/aarch64-oe-linux-gcc6.4 $SNPE_ROOT/bin/arm-oe-linux-gcc6.4hf |
| libSNPE.so | library | SNPE runtime for host and device development | $SNPE_ROOT/lib/x86_64-linux-clang $SNPE_ROOT/lib/arm-android-clang6.0 $SNPE_ROOT/lib/aarch64-android-clang6.0 $SNPE_ROOT/lib/arm-linux-gcc4.9sf $SNPE_ROOT/lib/aarch64-linux-gcc4.9 $SNPE_ROOT/lib/aarch64-oe-linux-gcc6.4 $SNPE_ROOT/lib/arm-oe-linux-gcc6.4hf |
| libSNPE_G.so | library | SNPE runtime with GPU support only, not suitable for use on host | $SNPE_ROOT/lib/arm-android-clang6.0 $SNPE_ROOT/lib/aarch64-android-clang6.0 |
| libsymphony-cpu.so | library | Symphony CPU runtime library. | $SNPE_ROOT/lib/x86_64-linux-clang $SNPE_ROOT/lib/arm-linux-gcc4.9sf $SNPE_ROOT/lib/aarch64-linux-gcc4.9 $SNPE_ROOT/lib/aarch64-oe-linux-gcc6.4 $SNPE_ROOT/lib/arm-oe-linux-gcc6.4hf |
| libsymphony-cpu.so | library | Symphony CPU runtime library for Android. | $SNPE_ROOT/lib/arm-android-clang6.0 $SNPE_ROOT/lib/aarch64-android-clang6.0 |
| libsnpe_adsp.so | library | Library for DSP runtime, for SDM820. | $SNPE_ROOT/lib/arm-android-clang6.0 $SNPE_ROOT/lib/aarch64-android-clang6.0 $SNPE_ROOT/lib/aarch64-linux-gcc4.9 $SNPE_ROOT/lib/aarch64-oe-linux-gcc6.4 $SNPE_ROOT/lib/arm-oe-linux-gcc6.4hf |
| libsnpe_dsp_domains.so | library | Library for Android DSP runtime, for non SDM 820 targets. | $SNPE_ROOT/lib/arm-android-clang6.0 $SNPE_ROOT/lib/aarch64-android-clang6.0 |
| libsnpe_dsp_domains_system.so | library | Library for Android DSP runtime loading from the /system partition, for non SDM 820 targets. | $SNPE_ROOT/lib/arm-android-clang6.0 $SNPE_ROOT/lib/aarch64-android-clang6.0 |
| libsnpe_dsp_skel.so | library | Hexagon DSP runtime library for SDM 820. | $SNPE_ROOT/lib/dsp |
| libsnpe_dsp_domains_skel.so | library | Hexagon DSP runtime library for v60 targets (excluding SDM820). | $SNPE_ROOT/lib/dsp |
| libsnpe_dsp_v65_domains_v2_skel.so | library | Hexagon DSP runtime library for v65 targets. | $SNPE_ROOT/lib/dsp |
| libsnpe_dsp_v66_domains_v2_skel.so | library | Hexagon DSP runtime library for v66 targets. | $SNPE_ROOT/lib/dsp |
| libc++_shared.so | library | Shared STL library implementation. | $SNPE_ROOT/lib/arm-android-clang6.0 $SNPE_ROOT/lib/aarch64-android-clang6.0 |
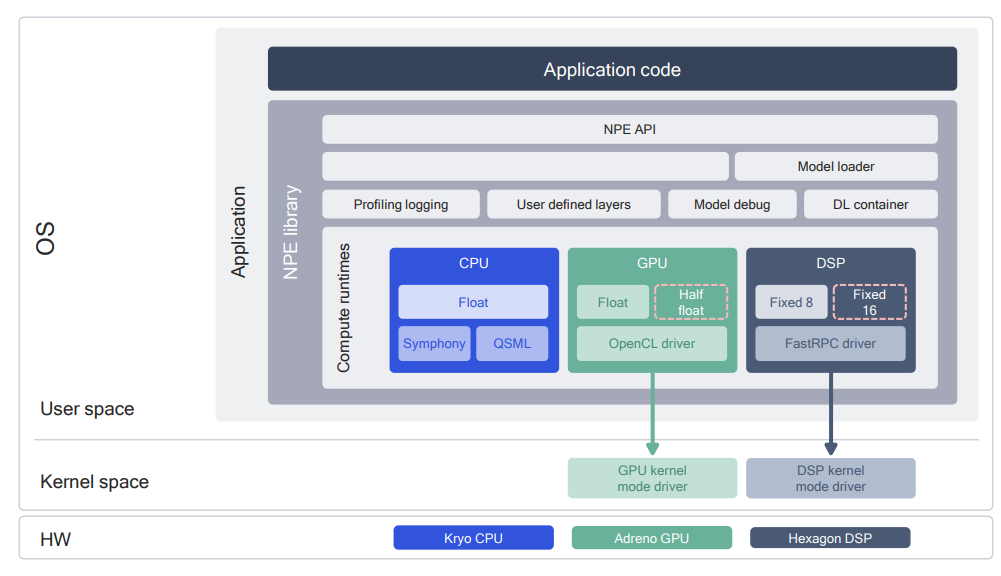
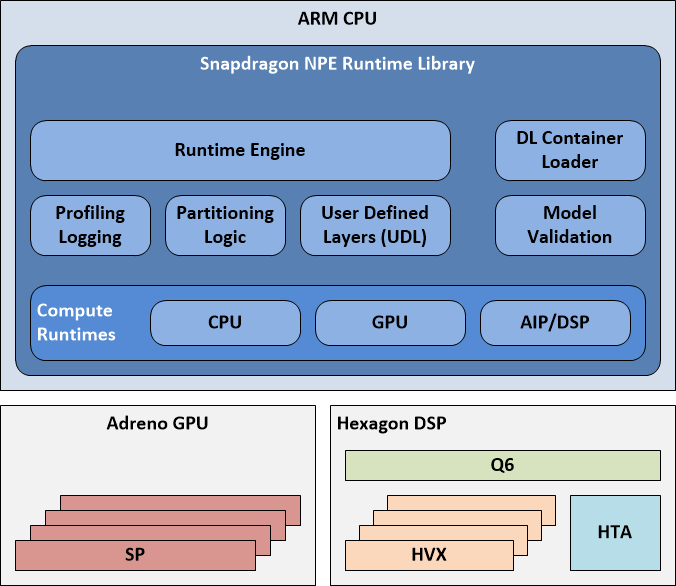
runtime架构
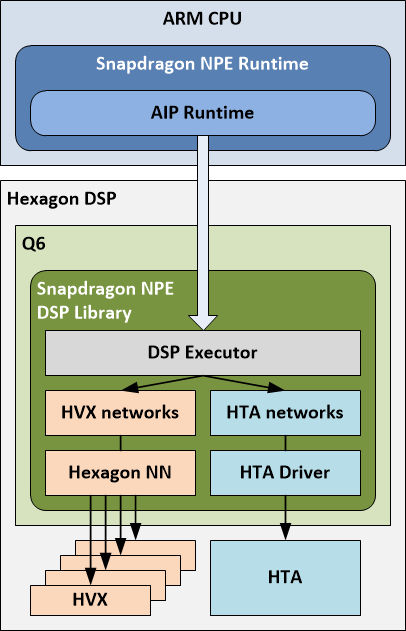
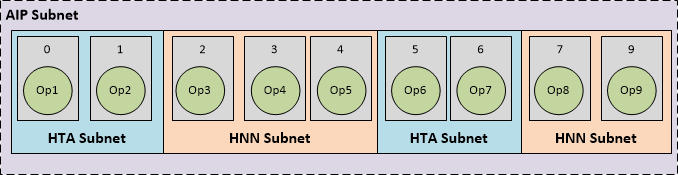
The AIP (AI Processor) Runtime is a software abstraction of Q6, HVX and HTA into a single entity (AIP) for the execution of a model across all three. A user, who loads a model into Snapdragon NPE and selects the AIP runtime as a target, will have parts of the model running on HTA, and parts on HVX, orchestrated by the Q6.
- HTA subnets: parts of the subnet which were compiled by the HTA Compiler, and whose metadata generated by the HTA compiler appears in the HTA sections of the DLC.
- HNN subnets: The rest of the subnet which can run on the DSP using Hexagon NN library, whose metadata appears in the HVX sections of the DLC.
使用方法
Select target architecture
SNPE provides Android binaries for armeabi-v7a and arm64-v8a architectures. For each architecture, there are binaries compiled with clang6.0 using libc++ STL implementation. The following shows the commands to select the desired binaries:
|
|
For simplicity, this tutorial sets the target binaries to arm-android-clang6.0, which use libc++_shared.so, for commands on host and on target.
Push binaries to target
Push SNPE libraries and the prebuilt snpe-net-run executable to /data/local/tmp/snpeexample on the Android target.
|
|
Set up enviroment variables
Set up the library path, the path variable, and the target architecture in adb shell to run the executable with the -h argument to see its description.
|
|
Push model data to Android target
To execute the Inception v3 classification model on Android target follow these steps:
|
|
Note: It may take some time to push the Inception v3 dlc file to the target.
using CPU Runtime
The Android C++ executable is run with the following commands:
|
|
The executable will create the results folder: /data/local/tmp/inception_v3/output. To pull the output:
|
|
Check the classification results by running the following python script:
|
|
The output should look like the following, showing classification results for all the images.
|
|
using DSP Runtime
Try running on an Android target with the –use_dsp option as follows: Note the extra environment variable ADSP_LIBRARY_PATH must be set to use DSP. (See DSP Runtime Environment for details.)
|
|
Pull the output into an output_android_dsp directory.
|
|
Check the classification results by running the following python script:
|
|
The output should look like the following, showing classification results for all the images.
|
|
Classification results are identical to the run with CPU runtime, but there are differences in the probabilities associated with the output labels due to floating point precision differences.
using AIP Runtime
The AIP runtime allows you to run the Inception v3 model on the HTA. Running the model using the AIP runtime requires setting the –runtime argument as ‘aip’ in the script $SNPE_ROOT/models/inception_v3/scripts/setup_inceptionv3.py to allow HTA-specific metadata to be packed into the DLC that is required by the AIP runtime. Refer to Getting Inception v3 for more details.
Other than that the additional settings for AIP runtime are quite similar to those for the DSP runtime.
Try running on an Android target with the –use_aip option as follows: Note the extra environment variable ADSP_LIBRARY_PATH must be set to use DSP. (See DSP Runtime Environment for details.)
|
|
Pull the output into an output_android_aip directory.
|
|
Check the classification results by running the following python script:
|
|
The output should look like the following, showing classification results for all the images.
|
|
版本演进
| Version | Date | Description |
|---|---|---|
| 1.35.0 | January 2020 | Introduce the User-Defined Operations (UDO) feature. Added support for SDM720G/SM7125. Added support to snpe-throughput-net-run for UserBuffer input tensors (both INT8 and INT16). Input batching support is added for networks that can run completely on AIP runtime. Add support for the tf.stack and tf.unstack ops to the DSP and CPU runtimes. Add support for the tf.stack, tf.unstack, tf.floor, tf.minimum to the TF converter. Fixed some small memory leaks that are seen when repeatedly calling dlopen()/dlclose() on libSNPE.so. Updated the Deconvolution operation on DSP with a new kernel that improves performance on various kernel sizes and strides. Fix ssd_detection CDSP crash on DSP runtime. Updated the HTA to partition the input layer, if it has a connection to a layer that is not included in the same partition. Improved the tiling configuration support for depth wise convolution layer. |
| 1.34.0 | January 2020 | Initial support for ops with 16-bit activations using HTA in both snpe-dlc-quantize and in the SNPE AIP runtime. New option for snpe-net-run to automatically turn unconsumed tensors of the network (tensors that are not inputs to a layer) into network outputs. Fixed inconsistent results on SM8250 in certain cases for depthwise convolutions. Add support for the depth2space operation on the GPU. Using optimized Softmax implementation in AIP networks when input activation has more than 5000 elements. Truncate detection output on DSP to return valid data only. Ensure weights are properly flushed to DDR for use during inference in the DSP runtime. Fix support for NV21 encoding in the DSP runtime. |
| 1.33.2 | November 2019 | Address accuracy issues for Deconvolution in the AIP runtime. Changed behavior of Crop layer resize, so it retains the number of copied elements on each dimension. Make quantizer –override_params work for AIP. Reordered PerformanceProfile_t to be ABI compatible with 1.32.0. Using optimized Softmax implementation in AIP networks when input activation has more than 5000 elements. |
| 1.33.1 | November 2019 | Fixed a build issue that incorrectly removed Symphony. |
| 1.33.0 | November 2019 | New performance modes have been added: LOW_POWER_SAVER: Run in lower clock than POWER_SAVER, at the expense of performance. HIGH_POWER_SAVER: Run in higher clock and provides better performance than POWER_SAVER. LOW_BALANCED: Run in lower balanced mode, provides lower performance than BALANCED. snpe-dlc-info adds a summary of the layer types in use in the model. Updated to use new BLAS functionality that leverages OpenMP. This adds a new dependency on the OpenMP shared library for Linux platforms. Added 32-bit bias support. Support init caching for SSD output layer on DSP. Fix memory leak causing increasing init time on DSP. Add converter support for dilated convolution when used with fakequant nodes. Multiple bugs fixed in snpe-onnx-to-dlc that were causing errors for models having torch.Mul op. Extends TF converter support to NMSv1 Op in addition to existing support for v2 and v3 NMS Ops. Tensorflow conversion bug fixed in infer_shape for StridedSlice Op. output_shape should not be a list of shapes but the shape of the one output. Fix bug with propagation of model version during conversion. If burst mode is set, set thread affinity to Big Cores during init and de-init, and restore to the previous setting after the actions are complete. Fix segfault when using user buffers with a resizable dimension. |
| 1.32.0 | Oct 2019 | Add Caffe MVN Layer support in the Caffe Converter, CPU Runtime, and DSP Runtime snpe-dlc-quantize: Enable the use of quantization parameters calculated during training when using dlc quantizer. To override the SNPE generated quantization parameters pass –override_params to snpe-dlc-quantize. Removed deprecated command line arguments from converters. All three converters now require passing -i/–input_network for model input paths. snpe-dlc-diff: Added command-line option [–diff_by_id/-i] to snpe-dlc-diff. This option allows users to compare 2 models in order(sorted by id) Added support for L2Norm layer to TensorFlow converter Optimized the DSP performance for the ‘Space To Depth’ layer Add support in the Java API for setInitCacheEnabled(), and setStorageDirectory() to enable DLC caching support. Allow graceful recovery after a fastrpc error - Recreate the userPD after the cDSP crashes so that the user can continue on the SNPE process with subsequent instances, instead of having to close the SNPE process. Note: all the instance associated to the previous userPD will be lost. snpe-dlc-viewer: Associate each layer type to a fixed color for consistency when using snpe-dlc-viewer Split the SNPE isRuntimeAvailable method into two separate functions to improve backward compatibility with existing client binaries that were built against the older signature. TF Converter: Fix Elementwise Broadcast support ONNX Converter: Fixed bug where output dimension was incorrect when keep_dims parameter was set to False for Argmax, ReduceSum and ReduceMax. ONNX Converter: Fixed bug where pad attribute was not properly parsed for Deconv Op. Caffe Converter: Fixed bug when converting SSD-based models when using Python 3. TF Converter: Fixed bug where converter was removing const Op input to reshape op when passed through identity op(s). i.e const-> identity -> reshape. Fixed bug where getOutputSize() would give the wrong result on output tensors in UserBuffer mode |
| 1.31.0 | September 2019 | New patterns were added to enable running the CLE algorithm on more op patterns and model architectures. Added Tensorflow converter support for Caffe-style SSD networks. Added support for HeatmapMaxKeypoint layer in the CPU runtime. Added support for ROI Align layer in CPU runtime. Added initial L2Norm layer support in CPU runtime. No support for axis parameter yet: normalization is performed along the inner-most dimension of the input tensor. Support for single-input Concatenation layers was added to CPU, GPU and DSP. Changed determination of number of batch dimensions in the Fully Connected layer so rank greater than 1 is always assumed to mean that there is 1 batch dimension. Removed constraint on the LSTM layer in the GPU runtime that prevented batch mode operation. Added support for Leaky-RELU in the TensorFlow converter. Both the actual Leaky-Relu op and the elementwise op representation are supported and map to SNPE’s Prelu op. Added Argmax support to the Caffe converter, and optimized performance on the DSP runtime. Added new column to snpe-dlc-info that displays the supported runtimes for each layer. Fixed an edge case where in certain conditions OpenCL would return CL_INVALID_WORK_GROUP_SIZE. Made isRuntimeAvailable Java API thread-safe. Replace unstable image from sample Android classifier application data set with an image that is more consistent. |
| 1.30.0 | August 2019 | Documentation has been added to reflect the new common converter command line options for input processing; Converters now propagate required batchnorm information for performing quantization optimizations; Support for the new bias correction quantization optimization which adjusts biases by analyzing float vs quantized activation errors and adjusting the model to compensate; ONNX converter now filters single input Concats as a no ops as SNPE didn’t support them; Converter input processing now uniformly handles different input types and encodings; ONNX converter now supports the ConvTranspose ‘output_padding’ attribute by adding an additional pad layer after the ConvTranspose op; Integrates the latest flatbuffer 1.11 library which brings speed improvements and options for model size reduction; GPU size limitations with the ArgMax op (when setting the keepDims op attribute to false) can be worked around by enabling CPU fallback; Fixed DSP error with MobileNet SSD on QCS403 and QCS405; Fixed the issue with partitioning of deconv layer in HTA; |
| 1.29.0 | July 2019 | Added support for dlc reorder tool;Optimization of HTA d32 conversions;Added tf space_to_depth op for SNPE CPU and DSP runtime;Benchmarking scripts enhanced for showing further break down of execution time, across various components;Added support for additional ONNX binary element-wise ops;Optimized deconv layer for improving performance;Fixed an issue related to runtime error in DSP runtime;Performance Optimization of SNPE GPU Runtime for Shufflenet V2 by using profiling level config |
| 1.28.0 | June 2019 | Added an optional argument to isRuntimeAvailable for the DSP runtime so that it doesn’t activate the DSP; Allow UB_T8 and UB_FLOAT output for snpe-net-run; Added a new command line option for snpe-dlc-diff to check layer names; Updated the –dlc argument to –output_path for snpe-caffe-to-dlc to align with the ONNX converter; Added –dry_run argument to snpe-onnx-to-dlc to allow evaluation for successful conversion on an ONNX model; Added support for the gather op in the DSP runtime; Added support to convert the TF MobileNet-V1-FPN-SSD model; Fixed a memory leak in the DSP runtime that is seen when repeatedly loading and unloading a network; Addressed issues on V66 DSPs related to acquiring VTCM memory; Fixed an issue related to multiple inputs for the Caffe converter; Fixed an issue in the TF converter related to element-wise sun and the atrous parameter; Fixed an issue in the TF converter related to tf.crop_and_resize when there are only 2 inputs.; Fixed additional cases of uncaught exceptions with the aarch64-android-clang6.0 platform; |
| 1.27.0 | May 2019 | Added new APIs support for setting output tensor names to snpeBuilder and to fetch output tensor names for a given output layer name; Improved the peak memory usage with DLC v3 format; Fixed few issues with performance and runtime failures on DSP runtime; Fixed few issues and improved error handling for platform validator; Fixed the issues with Pooling and Instance norm layers of Tensorflow converter; Removed *-android-gcc4.9 platform support. This compiler has been retired for the Android NDK, so all support is transitioning to using Clang for Android; Removed arm-linux-gcc4.8hf platform. The development platform has been retired; |
| 1.26.0 | Apr 2019 | Added support for the ONNX Gather Op in the ONNX Converter and CPU runtime; Optimized DeConvolution Layer for the DSP runtime; Support for tf.nn.moments in the TF converter, CPU and DSP runtimes; Added TF Reflect Pad support for the DSP runtime; Add symmetric quantizer option in snpe-dlc-quantize; Add support for batch > 1 when using the Scale Layer on the DSP runtime; Updated Platform Validator python script to be OS-independent; Added additional optimizations for HTA input conversion; |
| 1.25.0 | Mar 2019 | Updated DLC format to improve load time performance and memory consumption. Old DLCs will continue to work as is, but new DLCs generated from 1.25 will use the new format; Added support for optimized; MultiClassNms and ArgMax ops on DSP runtime; Added option to request larger memory allocations on the DSP for improved init time, at the expense of more memory use; Improved concurrency for multiple; SNPE objects running simultaneously on DSP; Improvements when using priority control on DSP; Added support for channel shuffle and ArgMax in the ONNX converter; Support multiple subnets within the AIP runtime; |
| 1.24.0 | Feb 2019 | Adding setProfilingLevel API support for AIP and CPU runtimes; Various stability issues on aip runtimes are addressed;Added support for Snapdragon 712;Support multi inputs and multiple outputs on each SNPE AIP’s subnet |
| 1.23.0 | Jan 2019 | Upgrade to Android NDK r17c to build SNPE; Improving initialization and de-initialization times; Various DSP timing fixes; Addressed some DSP concurrency edge cases that could impact output values; TF converter support for non max suppression, crop and resize Ops |
| 1.22.0 | Nov 2018 | Support for several new ops on DSP runtime; Upgrade to Android NDK r16b to build SNPE; setProfilingLevel API support in DSP runtime; Added new tool snpe-throughput-net-run |
| 1.21.0 | Oct 2018 | Tensorflow converter and CPU runtime support for various ops; DSP runtime support for Eltwise Realdiv and Square ops; GPU support for resize_align_corners layer |
| 1.20.0 | Sep 2018 | Support for QCS605 LE platform; NDK version upgrade to r14b; Tensorflow converter support for elementwise sqrt and softmax with dimension > 2; Platform validation command line tool |
| 1.19.0 | Aug 2018 | ELU op support for Tensorflow/Onnx Converters and CPU/GPU runtimes; BoxWithNMSLimit and BBoxTransform ops support in caffe2 converter; Support for Caffe Power Layer in GPU |
| 1.18.0 | Jul 2018 | Support for pad and elementwise subtraction on GPU; ONNX converter support for shape and pad ops; Tensorflow converter support for additional ops |
| 1.17.0 | Jun 2018 | Support for Scale Layer in Caffe converter and DSP runtime, DSP support for batch>1 and ChannelShuffle, Updated SDK examples for Inception v3 2016 model |
| 1.16.2 | May 2018 | Remove linkage to libstdc++.so in DSP loader libraries |
| 1.16.1 | May 2018 | Remove linkage to libstdc++.so, DSP runtime fixes, fix for 1D BatchNorm |
| 1.16.0 | May 2018 | Batch>1 support (except DSP runtime); layer optimizations for DSP runtime; Caffe2 ChannelShuffle support (except DSP runtime) |
| 1.15.2 | Mar 2018 | Fix for GPU runtime memory leak and reshape to/from 1D |
| 1.15.1 | Apr 2018 | Fix for converter for instance normalization followed by scale |
| 1.15.0 | Apr 2018 | Support for instance normalization for Caffe and Caffe2, MobilenetSSD (Caffe) |
| 1.14.1 | Mar 2018 | Minor fixes |
| 1.14.0 | Mar 2018 | ONNX converter (alpha), multiple enhancements and fixes |
| 1.13.0 | Feb 2018 | GPU and DSP v65 performance improvements. GPU floating point 16 support. |
| 1.12.0 | Jan 2018 | Support for Android LLVM/libc++, MobilenetSSD (TensorFlow) |
| 1.10.1 | Dec 2017 | Fix a bug in the DSP runtime when using mixed userbuffer input types |
| 1.10.0 | Dec 2017 | Support for Mobilenet on DSP, enhanced DSP runtime, Snapdragon Flight Board, updates for UserBuffers |
| 1.8.0 | Nov 2017 | Mobilenet support on CPU, GPU, Support for Snapdragon 636 and Android 64 bit |
| 1.6.0 | Oct 2017 | Support for Snapdragon 450, minor updates and fixes |
| 1.4.0 | Aug 2017 | Support for Snapdragon 630, FasterRCNN and ADSP on AGL |
| 1.2.2 | July 2017 | QDN release |
| 1.2.0 | June 2017 | Beta Caffe2 Converter |
| 1.0.2 | May 2017 | Support for 820AGL platform, Snapdragon 660, and Compute DSP on Android |
| 1.0.1 | Apr 2017 | Documentation update only |
| 1.0 | Apr 2017 |
Machine vision SDK
主要面向机器视觉领域,提供C形式的头文件和动态库,提供相机图像矫正,特征识别,障碍物检测等加速功能。
开发平台
不同类型的平台单独发布,例如8x09,8x74,8x96,845等。
提供下述系统下的开发SDK,运行在嵌入式linux上。
- linux
- macOS
- windows
依赖
- Platform image from Intrinsyc Flight_x.y.z_JFlash.zip
- Flight controller add-on from Intrinsyc Flight_x.y.z_qcom_flight_controller_hexagon_sdk_add_on.zip
支持算法列表
- Visual-Inertial Simultaneous Localization and Mapping (VISLAM)
- Uses an extended Kalman filter to fuse IMU and camera tracking data to provide a 6 degree of freedom pose estimate in real-world coordinates.
- Provides a 3D point cloud based upon tracked feature points
- Optionally accepts and fuses in GPS data
- Depth From Stereo (DFS)
- Uses 2 time-synchronized cameras to generate a per-pixel dense depth map
- Downward Facing Tracker (DFT)
- Provides an “optic-flow”-like tracking algorithm to generate a displacement in pixels on a camera pointed 90° downwards
- Sequence Reader/Writer (SRW)
- Read and write sequences of camera and IMU sensor data
- Voxel Map (VM)
- Combines the camera’s current 6DOF position with a depth map to generate a volumetric representation of its perceived world in 3D
- Performs collision checking
- Camera Auto Calibration (CAC)
- Use image and IMU data to estimate calibration parameters for the camera
- Camera Parameter Adjustment (CPA)
- Use current image data to recommend camera parameter changes
- Stereo Auto-Calibration (SAC) (new in v1.1.4)
- Uncalibrated image pairs of scene yield extrinsic calibration parameters
文件列表
每项功能对应一个头文件,so库按照模块分成独立的库发布
|
|
api列表
mv.h
|
|
mvVM.h
|
|
mvCAC.h
|
|
mvCPA.h
|
|
mvDFS.h
|
|
mvDFT.h
|
|
mvSAC.h
|
|
mvSRW.h
|
|
mvVISLAM.h
|
|
应用示例
https://github.com/ATLFlight/ATLFlightDocs
传统的C库发布方式,集成头文件和动态库即可使用功能。

版本演进
| 版本 | 发布时间 | release note |
|---|---|---|
| 1.2.7 | 03 Jul 19 | 无release note,着重于bug fix,功能完善 |
| 1.1.9 | 16 Oct 18 | Changes to VISLAM in this version include:Added GPS integrationImproved tracking drift performance generally and specifically in smaller areasImproved tracking CPU utilization |
| 1.1.8 | 24 Jan 18 | Optionally accepts and fuses GPS data in Visual-Inertial Simultaneous Localization and Mapping (VISLAM). |
fastcv
移动设备端运行的机器视觉库,可以运行在所有的arm处理器上,为高通骁龙处理器优化。包含fastcv for snapdragon和fastcv for arm两条path,API相同。
开发平台
提供下述系统下的开发SDK,目前版本支持运行在android系统上,后续版本支持运行在ios,windows phone系统
- macOS
- windows
- linux
面向领域
- 手势识别
- 脸部跟踪,检测,识别
- 文字识别及跟踪
- 增强现实
功能模块
- Math / Vector Operations:数学运算库
- Image processing:
- Image transformation
- Feature detection
- Object detection
- 3D reconstruction
- Color conversion
- Clustering and search
- Motion and object tracking
- Shape and drawing
- Memory Management
- Miscellaneous
- Machine Learning
依赖
- JDK
- Eclipse IDE
- Android SDK Downloader
- Android ADT
- Android SDK platform support
- Cygwin Environment
- Android NDK
文件列表
一个头文件,一个静态库
|
|
静态库libfastcv.a解压缩可以看到链接前的.o文件,看起来就是一些算法的集合,一般有2个版本:正常的和带V后缀的版本(数据是存在vector里面的)
|
|
特征检测
https://developer.qualcomm.com/docs/fastcv/api/group__feature__detection.html
快速角点检测,Harris角点检测,canny边缘检测,hough线条检测算法等。API无互相依赖。
| Functions | |
|---|---|
| FASTCV_API void | fcvCornerFast9u8 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, int barrier, unsigned int border, uint32_t *__restrict xy, unsigned int nCornersMax, uint32_t *__restrict nCorners) |
| Extracts FAST corners from the image. This function tests the whole image for corners (apart from the border). FAST-9 looks for continuous segments on the pixel ring of 9 pixels or more. | |
| FASTCV_API void | fcvCornerFast9InMasku8 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, int barrier, unsigned int border, uint32_t *__restrict xy, unsigned int nCornersMax, uint32_t *__restrict nCorners, const uint8_t *__restrict mask, unsigned int maskWidth, unsigned int maskHeight) |
| Extracts FAST corners from the image. This function takes a bit mask so that only image areas masked with ‘0’ are tested for corners (if these areas are also not part of the border). FAST-9 looks for continuous segments on the pixel ring of 9 pixels or more. | |
| FASTCV_API void | fcvCornerFast10u8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, int32_t barrier, uint32_t border, uint32_t *__restrict xy, uint32_t nCornersMax, uint32_t *__restrict nCorners) |
| Extracts FAST corners from the image. This function tests the whole image for corners (apart from the border). FAST-10 looks for continuous segments on the pixel ring of 10 pixels or more. | |
| FASTCV_API void | fcvCornerFast10InMasku8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, int32_t barrier, uint32_t border, uint32_t *__restrict xy, uint32_t nCornersMax, uint32_t *__restrict nCorners, const uint8_t *__restrict mask, uint32_t maskWidth, uint32_t maskHeight) |
| Extracts FAST corners from the image. This function takes a bit mask so that only image areas masked with ‘0’ are tested for corners (if these areas are also not part of the border). FAST-10 looks for continuous segments on the pixel ring of 10 pixels or more. | |
| FASTCV_API void | fcvCornerHarrisu8 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, unsigned int border, uint32_t *__restrict xy, unsigned int nCornersMax, uint32_t *__restrict nCorners, int threshold) |
| Extracts Harris corners from the image. This function tests the whole image for corners (apart from the border). | |
| FASTCV_API unsigned int | fcvLocalHarrisMaxu8 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, unsigned int posX, unsigned int posY, unsigned int *maxX, unsigned int *maxY, int *maxScore) |
| Local Harris Max applies the Harris Corner algorithm on an 11x11 patch within an image to determine if a corner is present. | |
| FASTCV_API void | fcvCornerHarrisInMasku8 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, unsigned int border, uint32_t *__restrict xy, unsigned int nCornersMax, uint32_t *__restrict nCorners, int threshold, const uint8_t *__restrict mask, unsigned int maskWidth, unsigned int maskHeight) |
| Extracts Harris corners from the image. This function takes a bit mask so that only image areas masked with ‘0’ are tested for corners (if these areas are also not part of the border). | |
| FASTCV_API void | fcvCornerHarrisAdaptiveu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t border, float32_t *__restrict xy, uint32_t nCornersMax, uint32_t *__restrict nCorners, int32_t threshold) |
| Extracts Harris corners from the image. This function tests the whole image for corners (apart from the border). It is an improved version which is more robust to low contrast images. | |
| FASTCV_API fcvStatus | fcvCornerHarrisScoreu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, float32_t *__restrict harrisResp, uint32_t respStride, uint32_t *__restrict xy, uint32_t nCornersMax, uint32_t *__restrict nCorners, float32_t threshold, float32_t sensitivity, uint32_t kernelSize, uint32_t blockSize, uint32_t nmsEnabled, float32_t minDistance, uint32_t normalizeResponse) |
| Extracts Harris corners from the image. ATTENTION: Compared to fcvCornerHarrisu8, this API gives more accurate results in exchange for slower execution time. . | |
| FASTCV_API void | fcvCornerFast9Scoreu8 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, int barrier, unsigned int border, uint32_t *__restrict xy, uint32_t *__restrict scores, unsigned int nCornersMax, uint32_t *__restrict nCorners) |
| Extracts FAST corners and scores from the image. | |
| FASTCV_API void | fcvCornerFast9InMaskScoreu8 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, int barrier, unsigned int border, uint32_t *__restrict xy, uint32_t *__restrict scores, unsigned int nCornersMax, uint32_t *__restrict nCorners, const uint8_t *__restrict mask, unsigned int maskWidth, unsigned int maskHeight) |
| Extracts FAST corners and scores from the image. | |
| FASTCV_API void | fcvCornerFast9Scoreu8_v2 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, int barrier, unsigned int border, uint32_t *__restrict xy, uint32_t *__restrict scores, unsigned int nCornersMax, uint32_t *__restrict nCorners, uint32_t nmsEnabled, void *__restrict tempBuf) |
| Extracts FAST corners and scores from the image. | |
| FASTCV_API void | fcvCornerFast9InMaskScoreu8_v2 (const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, int barrier, unsigned int border, uint32_t *__restrict xy, uint32_t *__restrict scores, unsigned int nCornersMax, uint32_t *__restrict nCorners, const uint8_t *__restrict mask, unsigned int maskWidth, unsigned int maskHeight, uint32_t nmsEnabled, void *__restrict tempBuf) |
| Extracts FAST corners and scores from the image based on the mask. The mask specifies pixels to be ignored by the detector. | |
| FASTCV_API void | fcvCornerFast10Scoreu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, int32_t barrier, uint32_t border, uint32_t *__restrict xy, uint32_t *__restrict scores, uint32_t nCornersMax, uint32_t *__restrict nCorners, uint32_t nmsEnabled, void *__restrict tempBuf) |
| Extracts FAST corners and scores from the image. | |
| FASTCV_API void | fcvCornerFast10InMaskScoreu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, int32_t barrier, uint32_t border, uint32_t *__restrict xy, uint32_t *__restrict scores, uint32_t nCornersMax, uint32_t *__restrict nCorners, const uint8_t *__restrict mask, uint32_t maskWidth, uint32_t maskHeight, uint32_t nmsEnabled, void *__restrict tempBuf) |
| Extracts FAST corners and scores from the image based on the mask. The mask specifies pixels to be ignored by the detector. | |
| FASTCV_API void | fcvBoundingRectangle (const uint32_t *__restrict xy, uint32_t numPoints, uint32_t *rectTopLeftX, uint32_t *rectTopLeftY, uint32_t *rectWidth, uint32_t *rectHeight) |
| Function to find the bounding rectangle of a set of points. | |
| FASTCV_API uint32_t | fcvKMeansTreeSearch36x10s8 (const int8_t *__restrict nodeChildrenCenter, const uint32_t *__restrict nodeChildrenInvLenQ32, const uint32_t *__restrict nodeChildrenIndex, const uint8_t *__restrict nodeNumChildren, uint32_t numNodes, const int8_t *__restrict key) |
| Search K-Means tree, where each node connects to up to 10 children, and the center (mean) is a 36-tuple vector of 8-bit signed value. | |
| FASTCV_API int | fcvLinearSearchPrepare8x36s8 (uint32_t *__restrict dbLUT, uint32_t numDBLUT, int8_t *__restrict descDB, uint32_t *__restrict descDBInvLenQ38, uint16_t *__restrict descDBTargetId, uint32_t *__restrict descDBOldIdx, uint32_t numDescDB) |
| Sorts in-place the pairs of <descDB, descDBInvLenQ38 > according to descDBTargetId. | |
| FASTCV_API void | fcvLinearSearch8x36s8 (const uint32_t *__restrict dbLUT, uint32_t numDBLUT, const int8_t *__restrict descDB, const uint32_t *__restrict descDBInvLenQ38, const uint16_t *__restrict descDBTargetId, uint32_t numDescDB, const int8_t *__restrict srcDesc, const uint32_t *__restrict srcDescInvLenQ38, const uint32_t *__restrict srcDescIdx, uint32_t numSrcDesc, const uint16_t *__restrict targetsToIgnore, uint32_t numTargetsToIgnore, uint32_t maxDistanceQ31, uint32_t *__restrict correspondenceDBIdx, uint32_t *__restrict correspondenceSrcDescIdx, uint32_t *__restrict correspondenceDistanceQ31, uint32_t maxNumCorrespondences, uint32_t *__restrict numCorrespondences) |
| Perform linear search of descriptor in a database. | |
| FASTCV_API void | fcvFindContoursExternalu8 (uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxNumContours, uint32_t *__restrict numContours, uint32_t *__restrict numContourPoints, uint32_t **__restrict contourStartPoints, uint32_t *__restrict pointBuffer, uint32_t pointBufferSize, int32_t hierarchy[][4], void *contourHandle) |
| Finds only extreme outer contours in a binary image. There is no nesting relationship between contours. It sets hierarchy[i][2]=hierarchy[i][3]=-1 for all the contours. | |
| FASTCV_API void | fcvFindContoursListu8 (uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxNumContours, uint32_t *__restrict numContours, uint32_t *__restrict numContourPoints, uint32_t **__restrict contourStartPoints, uint32_t *__restrict pointBuffer, uint32_t pointBufferSize, void *contourHandle) |
| Finds contours in a binary image without any hierarchical relationships. | |
| FASTCV_API void | fcvFindContoursCcompu8 (uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxNumContours, uint32_t *__restrict numContours, uint32_t *__restrict holeFlag, uint32_t *__restrict numContourPoints, uint32_t **__restrict contourStartPoints, uint32_t *__restrict pointBuffer, uint32_t pointBufferSize, int32_t hierarchy[][4], void *contourHandle) |
| Finds contours in a binary image and organizes them into a two-level hierarchy. At the top level, there are external boundaries of the components. At the second level, there are boundaries of the holes. If there is another contour inside a hole of a connected component, it is still put at the top level. | |
| FASTCV_API void | fcvFindContoursTreeu8 (uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxNumContours, uint32_t *__restrict numContours, uint32_t *__restrict holeFlag, uint32_t *__restrict numContourPoints, uint32_t **__restrict contourStartPoints, uint32_t *__restrict pointBuffer, uint32_t pointBufferSize, int32_t hierarchy[][4], void *contourHandle) |
| Finds contours in a binary image and reconstructs a full hierarchy of nested contours. | |
| FASTCV_API void * | fcvFindContoursAllocate (uint32_t srcStride) |
| Allocates assistant and intermediate data for contour. | |
| FASTCV_API void | fcvFindContoursDelete (void *contourHandle) |
| Deallocates assistant and intermediate data for contour. | |
| FASTCV_API int | fcvKDTreeCreate36s8f32 (const int8_t *__restrict vectors, const float32_t *__restrict invLengths, int numVectors, fcvKDTreeDatas8f32 **kdtrees) |
| create KDTrees for dataset of 36D vectors | |
| FASTCV_API int | fcvKDTreeDestroy36s8f32 (fcvKDTreeDatas8f32 *kdtrees) |
| release KDTrees data structures | |
| FASTCV_API int | fcvKDTreeQuery36s8f32 (fcvKDTreeDatas8f32 *kdtrees, const int8_t *__restrict query, float32_t queryInvLen, int maxNNs, float32_t maxDist, int maxChecks, const uint8_t *__restrict mask, int32_t *numNNsFound, int32_t *__restrict NNInds, float32_t *__restrict NNDists) |
| find nearest neighbors (NN) for query | |
| FASTCV_API void | fcvHoughCircleu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, fcvCircle *__restrict circles, uint32_t *__restrict numCircle, uint32_t maxCircle, uint32_t minDist, uint32_t cannyThreshold, uint32_t accThreshold, uint32_t minRadius, uint32_t maxRadius, void *__restrict data) |
| Finds circles in a grayscale image using Hough transform. | |
| FASTCV_API void | fcvHoughLineu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, float32_t threshold, uint32_t maxLines, uint32_t __restrict pNumLines, fcvLine__restrict pLines) |
| Performs Hough Line detection. | |
| FASTCV_API void | fcvImageMomentsu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, fcvMoments *moments, uint8_t binary) |
| Computes weighted average (moment) of the image pixels’ intensities. | |
| FASTCV_API void | fcvImageMomentss32 (const int32_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, fcvMoments *moments, uint8_t binary) |
| Computes weighted average (moment) of the image pixels’ intensities. | |
| FASTCV_API void | fcvImageMomentsf32 (const float32_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, fcvMoments *moments, uint8_t binary) |
| Computes weighted average (moment) of the image pixels’ intensities. | |
| FASTCV_API void | fcvImageDetectEdgePixelsu8 (const int16_t *__restrict gxgy, const uint32_t *__restrict mag, uint32_t gradStride, uint32_t topLeftX, uint32_t topLeftY, uint32_t width, uint32_t height, uint32_t gridSize, float32_t threshold, uint32_t nEdgePixelsMax, uint32_t *__restrict nEdgePixels, uint32_t *__restrict coordEdgePixels) |
| Extracts edge locations from the image. This function tests for edges a grid of pixels within a bounding box. | |
| FASTCV_API fcvStatus | fcvGLBPu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t radius, uint32_t neighbors, uint8_t *__restrict dst, uint32_t dstStride) |
| Computes the Generalized Local Binary Pattern Features for a single channel image. | |
| FASTCV_API fcvStatus | fcvCornerRefineSubPixu8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t blockWidth, uint32_t blockHeight, uint32_t maxIterations, float32_t stopCriteria, const uint32_t *__restrict xyInitial, uint32_t nCorners, float32_t *__restrict xyOut) |
| Refine corner location. | |
| FASTCV_API fcvStatus | fcvGoodFeatureToTracku8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, float32_t distanceMin, uint32_t border, float32_t barrier, uint32_t *__restrict xy, uint32_t maxnumcorners, uint32_t *__restrict numcorners) |
| Extract strong corners from image to track. | |
| FASTCV_API fcvStatus | fcvFindMultipleMaximau8 (const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, const float32_t *__restrict pos, const float32_t *__restrict normal, uint32_t maxDistance, uint32_t maxNumMaxima, int32_t minGradient, float32_t maxAngleDiff, float32_t *__restrict maxima, uint32_t *__restrict numMaxima) |
| Find multiple maxima along the normal direction of the line. | |
| FASTCV_API fcvStatus | fcvImageDetectLineSegmentsu8 (const fcvPyramidLevel_v2 *__restrict srcPyr, uint32_t pyrLevel, uint32_t doBlurImage, float32_t maxLineAngle, uint32_t minLineLength, uint32_t minMagnitude, uint32_t maxLineNum, uint32_t *__restrict indexBuffer, fcvLineSegment *__restrict lineSegments, uint32_t *__restrict numLineSegments) |
| Extract the straight line segments from the image. |
物体检测
https://developer.qualcomm.com/docs/fastcv/api/group__object__detection.html
基于NCC模板匹配算法的物体检测,少量API需要先init再使用,使用完释放。例如fcvMserInit, fcvMseru8, fcvMserRelease。无继承关系。
NCC是一种基于统计学计算两组样本数据相关性的算法,其取值范围为[-1, 1]之间,而对图像来说,每个像素点都可以看出是RGB数值,这样整幅图像就可以看成是一个样本数据的集合,如果它有一个子集与另外一个样本数据相互匹配则它的ncc值为1,表示相关性很高,如果是-1则表示完全不相关,基于这个原理,实现图像基于模板匹配识别算法,其中第一步就是要归一化数据,数学公式如下:

| Functions | |
|---|---|
| FASTCV_API int | fcvDescriptor17x17u8To36s8 (const uint8_t *__restrict patch, int8_t *__restrict descriptorChar, int32_t *__restrict descriptorNormSq) |
| Create a 36-dimension gradient based descriptor on 17x17 patch. | |
| FASTCV_API int | fcvMserInit (const unsigned int width, const unsigned int height, unsigned int delta, unsigned int minArea, unsigned int maxArea, float maxVariation, float minDiversity, void **mserHandle) |
| Function to initialize MSER. To invoke MSER functionality, 3 functions have to be called: fcvMserInit, fcvMseru8, fcvMserRelease. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserInit (width,……..,&mserHandle)) { fcvMseru8 (mserHandle,…); fcvMserRelease(mserHandle); }. | |
| FASTCV_API void | fcvMserRelease (void *mserHandle) |
| Function to release MSER resources. | |
| FASTCV_API void | fcvMseru8 (void *mserHandle, const uint8_t *__restrict srcPtr, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, unsigned int maxContours, unsigned int *__restrict numContours, unsigned int *__restrict numPointsInContour, unsigned int pointsArraySize, unsigned int *__restrict pointsArray) |
| Function to invoke MSER. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserInit (width,……..,&mserHandle)) { fcvMseru8 (mserHandle,…); fcvMserRelease(mserHandle); }. | |
| FASTCV_API void | fcvMserExtu8 (void *mserHandle, const uint8_t *__restrict srcPtr, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, unsigned int maxContours, unsigned int *__restrict numContours, unsigned int *__restrict numPointsInContour, unsigned int *__restrict pointsArray, unsigned int pointsArraySize, unsigned int *__restrict contourVariation, int *__restrict contourPolarity, unsigned int *__restrict contourNodeId, unsigned int *__restrict contourNodeCounter) |
| Function to invoke MSER, with additional outputs for each contour. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserInit (width,……..,&mserHandle)) { fcvMserExtu8 (mserHandle,…); fcvMserRelease(mserHandle); }. | |
| FASTCV_API int | fcvMseru8_v2 (void *mserHandle, const uint8_t *__restrict srcPtr, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxContours, uint32_t *__restrict numContours, uint16_t *__restrict recArray, uint32_t *__restrict numPointsInContour, uint32_t pointsArraySize, uint16_t *__restrict pointsArray) |
| Function to invoke MSER with a smaller memory footprint and the (optional) output of contour bound boxes. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserInit (width,……..,&mserHandle)) { if ( !fcvMseru8_v2 (mserHandle,…) ) { Error handle } fcvMserRelease(mserHandle); }. | |
| FASTCV_API int | fcvMserExtu8_v2 (void *mserHandle, const uint8_t *__restrict srcPtr, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxContours, uint32_t *__restrict numContours, uint16_t *__restrict recArray, uint32_t *__restrict numPointsInContour, uint32_t pointsArraySize, uint16_t *__restrict pointsArray, uint32_t *__restrict contourVariation, int8_t *__restrict contourPolarity, uint32_t *__restrict contourNodeId, uint32_t *__restrict contourNodeCounter) |
| Function to invoke MSER with a smaller memory footprint, the (optional) output of contour bound boxes, and additional information. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserInit (width,……..,&mserHandle)) { if ( !fcvMserExtu8_v2 (mserHandle,…) ) { Error handle } fcvMserRelease(mserHandle); }. | |
| FASTCV_API int | fcvMserExtu8_v3 (void *mserHandle, const uint8_t *__restrict srcPtr, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxContours, uint32_t *__restrict numContours, uint16_t *__restrict recArray, uint32_t *__restrict staPointsInPath, uint32_t *__restrict numPointsInContour, uint32_t pathArraySize, uint16_t *__restrict pathArray, uint32_t *__restrict contourVariation, int8_t *__restrict contourPolarity, uint32_t *__restrict contourNodeId, uint32_t *__restrict contourNodeCounter) |
| Function to invoke MSER with a smaller memory footprint, the (optional) output of contour bound boxes, and additional information. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserInit (width,……..,&mserHandle)) { if ( !fcvMserExtu8_v3 (mserHandle,…) ) { Error handle } fcvMserRelease(mserHandle); }. | |
| FASTCV_API int | fcvMserNN8Init (const uint32_t width, const uint32_t height, uint32_t delta, uint32_t minArea, uint32_t maxArea, float32_t maxVariation, float32_t minDiversity, void **mserHandle) |
| Function to initialize 8-neighbor MSER. To invoke 8-neighbor MSER functionality, 3 functions have to be called: fcvMserNN8Init, fcvMserNN8u8, fcvMserRelease. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserNN8Init (width,……..,&mserHandle)) { if ( !fcvMserNN8u8 (mserHandle,…) ) { Error handle } fcvMserRelease(mserHandle); }. | |
| FASTCV_API int | fcvMserNN8u8 (void *mserHandle, const uint8_t *__restrict srcPtr, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxContours, uint32_t *__restrict numContours, uint16_t *__restrict recArray, uint32_t *__restrict numPointsInContour, uint32_t pointsArraySize, uint16_t *__restrict pointsArray) |
| Function to invoke 8-neighbor MSER. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserNN8Init (width,……..,&mserHandle)) { if ( !fcvMserNN8u8 (mserHandle,…) ) { Error handle } fcvMserRelease(mserHandle); }. | |
| FASTCV_API int | fcvMserExtNN8u8 (void *mserHandle, const uint8_t *__restrict srcPtr, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t maxContours, uint32_t *__restrict numContours, uint16_t *__restrict recArray, uint32_t *__restrict numPointsInContour, uint32_t pointsArraySize, uint16_t *__restrict pointsArray, uint32_t *__restrict contourVariation, int8_t *__restrict contourPolarity, uint32_t *__restrict contourNodeId, uint32_t *__restrict contourNodeCounter) |
| Function to invoke 8-neighbor MSER, , with additional outputs for each contour. Image width has to be greater than 50, and image height has to be greater than 5. Pixels at the image boundary are not processed. If boundary pixels are important for a particular application, please consider padding the input image with dummy pixels of one pixel wide. Here is the typical usage: void *mserHandle; if (fcvMserNN8Init (width,……..,&mserHandle)) { if ( !fcvMserExtNN8u8 (mserHandle,…) ) { Error handle } fcvMserRelease(mserHandle); }. | |
| FASTCV_API int | fcvDescriptorSampledMeanAndVar36f32 (const float *__restrict src, int first, int last, int32_t *vind, float *__restrict means, float *__restrict vars, float *__restrict temp) |
| compute approximate mean and variance for the range of NFT4 float descriptors where descriptor elements along dimension are treated as random vars | |
| FASTCV_API int | fcvNCCPatchOnCircle8x8u8 (const uint8_t *__restrict patch, const uint8_t *__restrict src, unsigned short srcWidth, unsigned short srcHeight, unsigned short search_center_x, unsigned short search_center_y, unsigned short search_radius, uint16_t *best_x, uint16_t *best_y, uint32_t *bestNCC, int findSubPixel, float *subX, float *subY) |
| Searches a 8x8 patch within radius around a center pixel for the max NCC. | |
| FASTCV_API int | fcvNCCPatchOnCircle8x8u8_v2 (const uint8_t *__restrict patch, const uint8_t *__restrict src, unsigned short srcWidth, unsigned short srcHeight, unsigned short search_center_x, unsigned short search_center_y, unsigned short search_radius, int filterLowVariance, uint16_t *best_x, uint16_t *best_y, uint32_t *bestNCC, int findSubPixel, float *subX, float *subY) |
| Searches a 8x8 patch within radius around a center pixel for the max NCC. | |
| FASTCV_API int | fcvNCCPatchOnSquare8x8u8 (const uint8_t *__restrict patch, const uint8_t *__restrict src, unsigned short srcWidth, unsigned short srcHeight, unsigned short search_center_x, unsigned short search_center_y, unsigned short search_w, uint16_t *best_x, uint16_t *best_y, uint32_t *bestNCC, int doSubPixel, float *subX, float *subY) |
| Searches a 8x8 patch within square region around a center pixel for the max NCC. | |
| FASTCV_API int | fcvNCCPatchOnSquare8x8u8_v2 (const uint8_t *__restrict patch, const uint8_t *__restrict src, unsigned short srcWidth, unsigned short srcHeight, unsigned short search_center_x, unsigned short search_center_y, unsigned short search_w, int filterLowVariance, uint16_t *best_x, uint16_t *best_y, uint32_t *bestNCC, int doSubPixel, float *subX, float *subY) |
| Searches a 8x8 patch within square region around a center pixel for the max NCC. | |
| FASTCV_API void | fcvSumOfAbsoluteDiffs8x8u8 (const uint8_t *__restrict patch, const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, uint16_t *__restrict dst) |
| Sum of absolute differences of an image against an 8x8 template. | |
| FASTCV_API void | fcvSumOfAbsoluteDiffs8x8u8_v2 (const uint8_t *__restrict patch, unsigned int patchStride, const uint8_t *__restrict src, unsigned int srcWidth, unsigned int srcHeight, unsigned int srcStride, uint16_t *__restrict dst, unsigned int dstStride) |
| Sum of absolute differences of an image against an 8x8 template. | |
| FASTCV_API void | fcvTrackLKOpticalFlowu8 (const uint8_t *__restrict src1, const uint8_t *__restrict src2, int srcWidth, int srcHeight, const fcvPyramidLevel *src1Pyr, const fcvPyramidLevel *src2Pyr, const fcvPyramidLevel *dx1Pyr, const fcvPyramidLevel *dy1Pyr, const float *featureXY, float *featureXY_out, int32_t *featureStatus, int featureLen, int windowWidth, int windowHeight, int maxIterations, int nPyramidLevels, float maxResidue, float minDisplacement, float minEigenvalue, int lightingNormalized) |
| Optical flow. Bitwidth optimized implementation. | |
| FASTCV_API void | fcvTrackLKOpticalFlowu8_v2 (const uint8_t *__restrict src1, const uint8_t *__restrict src2, uint32_t width, uint32_t height, uint32_t stride, const fcvPyramidLevel_v2 *src1Pyr, const fcvPyramidLevel_v2 *src2Pyr, const float32_t *featureXY, float32_t *featureXY_out, int32_t *featureStatus, int32_t featureLen, int32_t windowWidth, int32_t windowHeight, int32_t maxIterations, int32_t nPyramidLevels) |
| Optical flow (with stride so ROI can be supported) | |
| FASTCV_API void | fcvTrackLKOpticalFlowf32 (const uint8_t *__restrict src1, const uint8_t *__restrict src2, unsigned int srcWidth, unsigned int srcHeight, const fcvPyramidLevel *src1Pyr, const fcvPyramidLevel *src2Pyr, const fcvPyramidLevel *dx1Pyr, const fcvPyramidLevel *dy1Pyr, const float *featureXY, float *featureXY_out, int32_t *featureStatus, int featureLen, int windowWidth, int windowHeight, int maxIterations, int nPyramidLevels, float maxResidue, float minDisplacement, float minEigenvalue, int lightingNormalized) |
| Optical flow. | |
| FASTCV_API int | fcvTrackBMOpticalFlow16x16u8 (const uint8_t *__restrict src1, const uint8_t *__restrict src2, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, uint32_t roiLeft, uint32_t roiTop, uint32_t roiRight, uint32_t roiBottom, uint32_t shiftSize, uint32_t searchWidth, uint32_t searchHeight, uint32_t searchStep, uint32_t usePrevious, uint32_t *numMv, uint32_t *locX, uint32_t *locY, uint32_t *mvX, uint32_t *mvY) |
| Block Optical Flow 16x16 - Tracks all 16x16 blocks in the Region of Interest (ROI) from Source-1 to Source-2. Generates Motion Vectors for blocks where motion is detected. | |
| FASTCV_API fcvStatus | fcvNCCPatchesOnRectu8 (const uint8_t *__restrict patches, uint32_t patchWidth, uint32_t patchHeight, const uint8_t *__restrict src, uint32_t srcWidth, uint32_t srcHeight, uint32_t srcStride, const uint32_t *__restrict searchCenterX, const uint32_t *__restrict searchCenterY, uint32_t searchWidth, uint32_t searchHeight, int32_t filterLowVariance, uint32_t *__restrict bestX, uint32_t *__restrict bestY, uint32_t *__restrict bestNCC, int32_t findSubPixel, float32_t *__restrict subX, float32_t *__restrict subY, uint32_t numSearches) |
| Searches a set of patches within the source image for the max NCCs. The search regions are corresponding to the patches in the search list. | |
| FASTCV_API fcvStatus | fcvTrackLKOpticalFlowu8_v3 (const uint8_t *__restrict src1, const uint8_t *__restrict src2, uint32_t width, uint32_t height, uint32_t stride, const fcvPyramidLevel_v2 *__restrict src1Pyr, const fcvPyramidLevel_v2 *__restrict src2Pyr, const float32_t *__restrict featureXY, const float32_t *__restrict featureXY_estimate, float32_t *__restrict featureXY_out, int32_t *__restrict featureStatus, int32_t featureLen, int32_t windowWidth, int32_t windowHeight, int32_t nPyramidLevels, fcvTerminationCriteria termCriteria, int32_t maxIterations, float32_t maxEpsilon, int32_t use_initial_estimate) |
| Optical flow (with stride so ROI can be supported) | |
| FASTCV_API fcvStatus | fcvExtractHOGu16 (const uint16_t *__restrict strength, uint32_t width, uint32_t height, uint32_t strengthStride, const uint16_t *__restrict orientation, uint32_t orientationStride, uint32_t cellSize, uint32_t blockSize, uint32_t blockStep, uint32_t binSize, fcvHOGNormMethod normMethod, uint16_t *__restrict hogVector, uint32_t flen, void *handle) |
| Extract Histogram of Oriented Gradients (HOG) descriptor given an image’s gradient strength and orientation. | |
| FASTCV_API fcvStatus | fcvHOGInit (uint32_t width, uint32_t height, uint32_t cellSize, uint32_t blockSize, uint32_t blockStep, uint32_t binSize, fcvHOGNormMethod normMethod, uint32_t *vecLength, void **hogHandle) |
| Calculate the length of the output vector for HOG extraction. | |
| FASTCV_API void | fcvHOGDeInit (void *hogHandle) |
| Function to release HOG resources. |
应用示例
参见sample下的fastcvdemo,这是一个标准的android应用,在jni部分调用了fastcv的函数。实现图片的处理及边缘检测。
版本演进
详见fastcv_releasenotes_1.7.1_may2019.pdf
版本号为A:B:C格式
A:API发生改变
B:增加新功能,原有API不变
C:实现改变
1.0.2:第一版
1.0.3:fcvSumOfSquaredDiffs36x4s8()改变
1.0.4:性能优化
1.1.0:添加_v2后缀新的API
1.1.1:修复问题,性能优化,添加demo app
1.2.0:添加图像color类型转换API,fcvColorRGB888ToRGBA8888u8,fcvColorRGB565ToBGR565u8,C接口这里有弊端,类型太多了,没法用模板。
1.2.1:修复问题,性能优化
1.2.2:引入llvm编译器,根据当前模式自动选择QDSP或者GPU实现类型。
1.3:添加更多的API,fcvBilateralFilter5x5u8,fcvBilateralFilter5x5u8
1.4:fcvFlipu8,fcvFlipu8函数定义改变,上一版本引入
1.5:fcvElementMultiplyu8u16,fcvElementMultiplyf32函数定义改变,添加大量新的API,fcvBitwiseAndu8,fcvFilterSobel5x5u8s16,fcvIFFTf32等
1.6:fcvBoxFilterNxNf32函数定义改变,新增fcv2PlaneWarpPerspectiveu8,fcvICPJacobianErrorSE3f32,fcvDepthFusion8x8x8xNs16,fcvImageDetectLineSegmentsu8,fcvFindMultipleMaximau8,fcvScaleDownBy2Gaussian3x3u8
1.7:新增API,fcvMinMaxLocf32_v2,fcvScaleu8_v2,android支持32,64位
1.7.1:llvm更新为3.7版本
参考点
- 版本号控制策略
- 如何新增,作废一个API:引入后缀_V2, _v3,大版本升级后取消老API,_v2转正,取消后缀。
- fastcv提供的算法列表
- 自定义算法支持
文章作者 carter2005
上次更新 2020-03-06