广播机制

文章目录
背景
tf,PyTorch,numpy的广播其实和python的是一样的,算子支持广播的话可以简化代码(减少准备数据的代码),减少内存消耗。
例如,一个3 * 3的张量,减去一个常量,如果不支持广播,需要先将常量复制成3 * 3的,然后2个张量做减法。支持广播的话,3 * 3的张量可以直接减去1的张量。
|
|
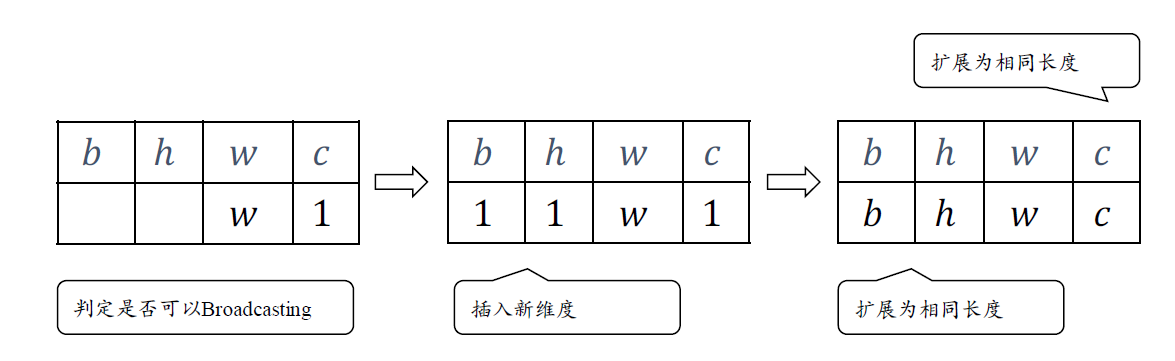
shape兼容检查
如果两个张量的后缘维度(从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为它们是广播兼容的。广播会在缺失维度和(或)轴长度为1的维度上进行。
|
|
广播计算
核心是计算stride,对于可以广播的维度,它对应的shape值是1,stride为0,这样其实索引的还是原先的数据。
|
|
文章作者 carter2005
上次更新 2020-03-18