AI加速卡

文章目录
广义上来讲,包括像GPU、FPGA以及 ASIC(专用芯片)这些提供AI算力的芯片都可以称之为AI芯片。
分类
按照任务划分,AI芯片可以分为训练芯片和推理芯片;
| 任务类别 | 特点 |
|---|---|
| 训练芯片 | 对算力、精度和通用性要求较高,一般部署在云端,多采用“CPU+加速芯片”这类异构计算模式 |
| 推理芯片 | 更加注重综合性能,更考虑算力耗能、延时、成本等因素,在云端和边终端都可以部署 |
按部署位置划分,可以分为云端芯片、边缘侧和终端芯片。
| 部署位置 | 特点 |
|---|---|
| 云端芯片 | 部署在公有云、私有云和混合云等大型数据中心,能满足海量数据处理和大规模计算,可通过多处理器并行完成各类AI算法的计算和传输,具有通用性 |
| 边缘/终端侧芯片 | 要求体积小、能耗少、性能略低,主要用于摄像头、手机、边缘服务器等终端设备中,满足有限的AI能力 |
硬件方案
| 厂商 | 类型 | 性能 | 特点 |
|---|---|---|---|
| nvidia | GPU+ASIC | AI算法训练的主要芯片配置是GPU+ASIC,全球主流的云端硬件平台都在使用英伟达的GPU 进行加速。而在推理服务上,主要还是采用CPU+GPU的方式进行异构计算,这得益于GPU强大的并行计算能力、通用性以及成熟的开发环境,但GPU的高能耗和昂贵成本,也成为众多云厂商的心中隐痛 | |
| tpu | TPU與同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。 | ||
| 高通 | Cloud AI 100 | 350TOPS | 每瓦特性能提升10倍 |
| amazon | AWS Inferentia | 128TOPS | 在AI推理实例inf1可搭载16个Inferentia芯片,提供最高2000TOPS算力 |
| 阿里巴巴 | 含光800 | 主要用于和电商业务相关的云端视觉场景,在RESNET50基准测试中获得单芯片性能第一的成绩。 | |
| 华为 | Atlas900 | 256-1024PFLOPS@F16 | 集成了数千颗昇腾910芯片,相当于50万台PC计算能力的强劲算力 |
| 燧原科技 | 云燧T10 | 20TFLOPS | 可以为大中小型数据中心提供了单节点、单机柜、集群三种模 |
| 寒武纪 | 思元290 | 理论峰值性能与华为昇腾 910 相当 | |
| intel | Nervana AI 芯片 | 都是专为云端环境特制的 ASIC 芯片,可以「几乎线性地」并接多个芯片,加速 AI 模型的开发。 | |
| amd | Instinct mi 50 | 13.3TFLOPS | 支持ROCm开放平台 |
| 赛灵思 | versal ACAP芯片 | Versal作为业界首款自适应计算加速平台,它的性能远远超过传统的中央处理器(CPU)、图像处理器(GPU)和现场可编程门阵列(FPGA) | |
| 训练芯片“昆仑818-300”、推理芯片“昆仑818-100” | 在150瓦的功率下能实现260 TOPS的处理能力 | 百度第一次发布XPU是在2017年加州Hot Chips大会上,这是一款256核、基于FPGA的云计算加速芯片,合作伙伴是赛思灵(Xilinx)。2018年7月4日,百度AI开发者大会上,“昆仑”首次面世 |
软件框架
寒武纪 - Cambricon NeuWare
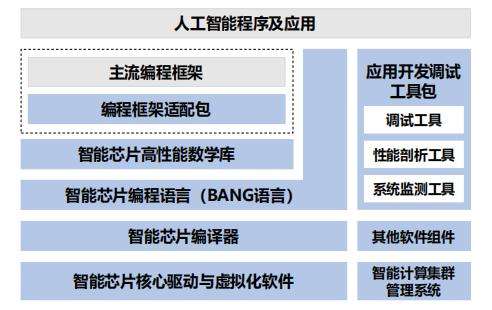
在 Cambricon NeuWare 的支持下,开发者可实现跨云、边、端硬件平台的 AI 应用开发,以 “一处开发、处处运行” 的模式,大幅提升 AI 应用在不同硬件平台的开发效率和部署速度,同时也使云、边、端异构硬件资源的统一管理、调度和协同计算成为可能。
燧原 TopsRider

AMD ROCm


Important features include the following:
- Multi-GPU coarse-grain shared virtual memory
- Process concurrency and preemption
- Large memory allocations
- HSA signals and atomics
- User-mode queues and DMA
- Standardized loader and code-object format
- Dynamic and offline-compilation support
- Peer-to-peer multi-GPU operation with RDMA support
- Profiler trace and event-collection API
- Systems-management API and tools
文章作者 carter2005
上次更新 2020-08-20