ioremap
 次阅读
次阅读
文章目录
硬件一般是通过寄存器,片上内存对外提供服务的,kernel根据PCIE设备config space来初始化设备。
|
|
|
|
一般来说,在系统运行时,外设的I/O内存资源的物理地址是已知的,由硬件的设计决定。但是CPU通常并没有为这些已知的外设I/O内存资源的物理地址预定义虚拟地址范围,驱动程序并不能直接通过物理地址访问I/O内存资源,而必须将它们映射到核心虚地址空间内(通过页表),然后才能根据映射所得到的核心虚地址范围,通过访内指令访问这些I/O内存资源。
cpu访问寄存器有2种方式:
- IO映射:ioremap,寄存器被映射到专门的IO地址空间,通过专门的函数来读写
- 内存映射:mmap,寄存器被映射到虚拟内存空间,cpu可以像访问内存一样操作,更为方便。
ioremap
ioremap方式虽然将寄存器映射到了虚拟的内存空间,但要特别注意,映射的虚拟地址是不能cpu直接访问的,得通过专门的函数访问(x86似乎直接访问也没问题,但在arm上,memset之类的函数是汇编优化实现的,会导致crash)。
- readb/writeb
- readw/writew
- readl/writel
- readq/writeq
- memcpy_fromio
- memcpy_toio
- memset_io
X86
| 函数名 | 功能 |
|---|---|
| ioremap | 标准版本,nocache |
| ioremap_nocache | nocache |
| ioremap_uc | 强nocache |
| ioremap_cache | cache |
| ioremap_wc | write combined,性能更好 |
| ioremap_wt | write through, |
Write-through(直写模式)在数据更新时,同时写入缓存Cache和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。 Write-back(回写模式)在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
X86定义的函数版本很多,还可以动态设置attribute,非常的灵活。
ARM64
| 函数名 | 功能 |
|---|---|
| ioremap | 标准版本,nocache,no gather, no reorder, early write acknowledgement |
| ioremap_nocache | 同上 |
| ioremap_wt | 同上 |
| ioremap_wc | nocache,write through,normal类型 |
|
|
ARM对于memory类型解释(https://blog.csdn.net/shenhuxi_yu/article/details/90617675)
ARM把memeory 分成两个类型device 与 normal, device 类型的memory的访问行为比较复杂,例如read clear, read inc addr(读同一个寄存器,实际会递增的去访问某一块memory),这些特性决定了cpu 不能像normal memory 那样对memroy 访问进行re-order,normal memory即是我们常理解的内存。
mmu 用如上这几种形式来描述memory block的不同属性,不同属性定义了不同的访问行为:
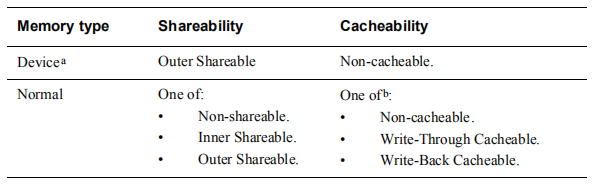
对normal memory:
shareable domain的概念。如何划分shareable domain是和系统设计相关,我们假设一个系统的domain分配如下: (1)所有的cpu core属于一个inner shareable domain (2)所有的cpu core和dma controller属于一个outer shareable domain 在ARM architecture中,对一个normal memory location而言,是否是coherent是和它的页表中的shareability attribute的设定相关。 (1)non-shareable。根本不会再多个agent之间共享,不存在coherent的问题。 (2)inner-shareable。说明inner shareable domain中的所有的agent在对该内存进行数据访问的时候,硬件会保证coherent。 (3)outer-shareable。说明outer shareable domain中的所有的agent在对该内存进行数据访问的时候,硬件会保证coherent。
Write-through(直写模式)在数据更新时,同时写入缓存Cache和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。 Write-back(回写模式)在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
对device memory:
对于device type,其总是non cacheable的,而且是outer shareable,因此它的attribute不多,主要有下面几种附加的特性:
(1)Gathering 或者non Gathering (G or nG)。这个特性表示对多个memory的访问是否可以合并,如果是nG,表示处理器必须严格按照代码中内存访问来进行,不能把两次访问合并成一次。例如:代码中有2次对同样的一个地址的读访问,那么处理器必须严格进行两次read transaction。
(2)Re-ordering (R or nR)。这个特性用来表示是否允许处理器对内存访问指令进行重排。nR表示必须严格执行program order。
(3)Early Write Acknowledgement (E or nE)。PE访问memory是有问有答的(更专业的术语叫做transaction),对于write而言,PE需要write ack操作以便确定完成一个write transaction。为了加快写的速度,系统的中间环节可能会设定一些write buffer。nE表示写操作的ack必须来自最终的目的地而不是中间的write buffer。
mmap
用户态应用是用mmap,可以像普通内存那样使用,没什么特别的注意事项。
修复方案
- kernel,efsmt工具refine代码,用专用函数操作寄存器和ioremap内存。
- 用户态用mmap出来的内存操作hbm。
文章作者 carter2005
上次更新 2020-11-21